In this last post of NSX-T backup & restore, we will perform the DR test and post tasks after the restore is complete. Just in case if you have missed, here are links to previous posts.
NSX-T 3.1 – Backup & Restore_Production DR Experience – Part1
NSX-T 3.1 – Backup & Restore_Production DR Experience – Part2
We move to next step by deploying an additional NSX-T manager.

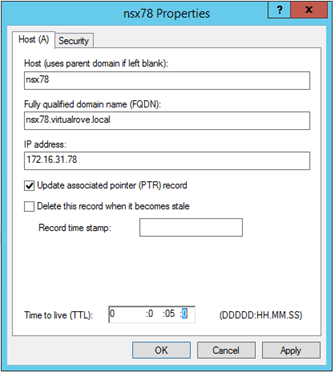
Deploy the new nsx-t manger on the DR site. Make sure to deploy same node for which last successfully backup was taken on the primary site. In my case, last successful backup was for ‘nsx78’ node. I have reserved the new ip address (172.16.31.178) for this node. Remember, we do not need to create DNS record for new node at this point. I am deploying the new nsx-t manager at Site-B (Singapore). Review the deployment parameters here…
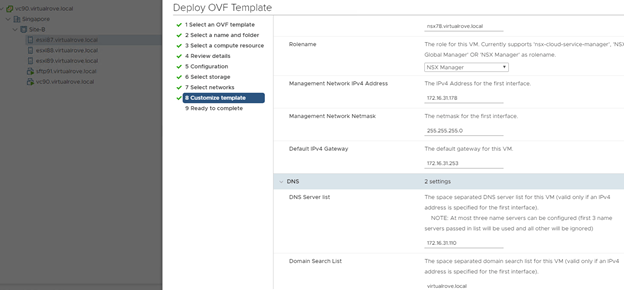
Next, Its time to shutdown the primary site nsx-t managers. Ideally, in DR scenario, NSX-T managers on the primary site will be already down. And that’s when we start performing the restore process.

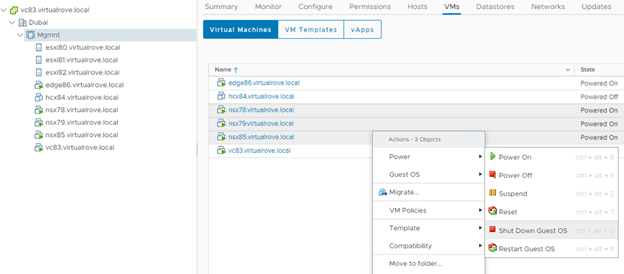
Next, We need to change the DNS records for primary site NSX-T managers to new IP’s from the secondary site. In production env, you might have different subnet on the DR site. I have the same subnet with different IP’s.


Login to the DC and update the DNS records.
Existing IP’s on DNS server.

Update to new IP’s.

All 4 DNS records have been updated.

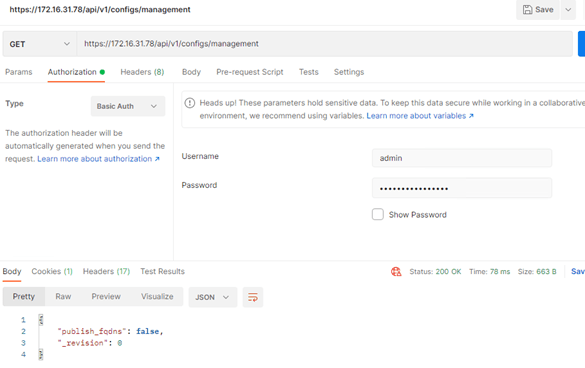
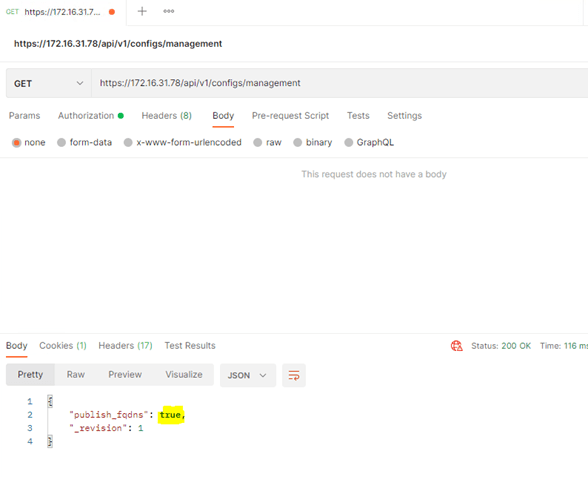
Next, we need to configure newly deployed NSX-T manger for FQDN using the API call.

https://172.16.31.178/api/v1/configs/management

Let’s start the restore process now.

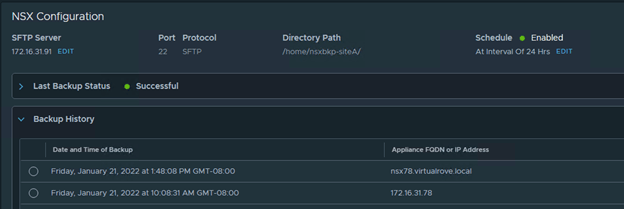
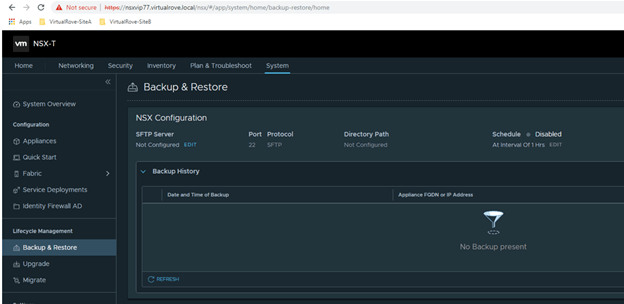
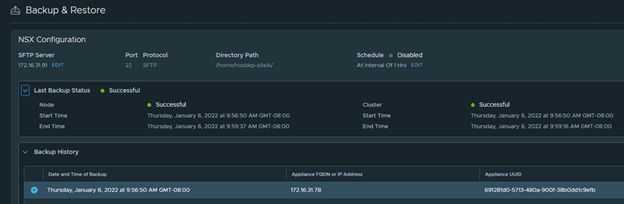
Configure the SFTP server on newly deployed NSX-T manger and check for recent backup that has been discovered by the appliance.
Note that we are getting EULA prompt. We get this prompt only on the newly deployed NSX-T manager.

Navigate to Backup config and enter sftp server details.

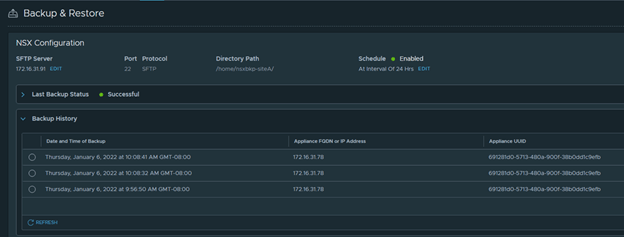
Note that the newly deployed appliance now discovers all successful backups.

Next,

Upon selecting recent backup, you should see ‘Restore’ option highlighted. If you do not see ‘Restore’ option, you will have to re-check all steps provided in this article.
Quick Tip here, if you do not see restore option, scroll down and select the backup where it lists the Appliance FQDN as your newly deployed appliance FQDN. 😊 We found this behavior while troubleshooting at customer location. And it does make sense too. That is why I mentioned earlier in this blog that, deploy the new appliance for which you see last successful backup for.

Note that we do not see any Tier-0 or segments in the newly deployed appliance.

Let’s begin the restore process,
Select the recent backup and restore…
You should see a prompt…
Restoring NSX Managers
If you are running NSX on Virtual Distributed Switch (VDS) and are attempting to perform a Restore operation to a backup file that contains N-VDS switches, then the restore operation might fail. Please
Please read the following steps carefully before you proceed:
- Step 1: Power Off.
- Power off all NSX Manager appliances that may be running from the earlier deployment.
- Step 2: Restore NSX Manager appliances.
- Restore NSX Manager appliances from the backup.
- Note: During the restore process, your deployment will be in read-only mode and the UI will be inaccessible. Automatic backups will be disabled.
- Step 3: Go to the Backup & Restore page.
- After the restore process ends, log in to your NSX Manager appliance and visit the Backup & Restore page to continue.
NOTE: If the restore fails, you must install a new NSX Manager appliance and try the restore process again.
Review and click Continue.
Restore process begins…

The restore process should start and you will lose the connectivity to new nsx-t manger after 10-15 mins.
Since the restore has started, you will have to re-login to new nsx-t manager with your old password from your primary site.

It would take significant amount of time to come back online. Once up, login to NSX-T manager and navigate the backup again. You should see prompt.
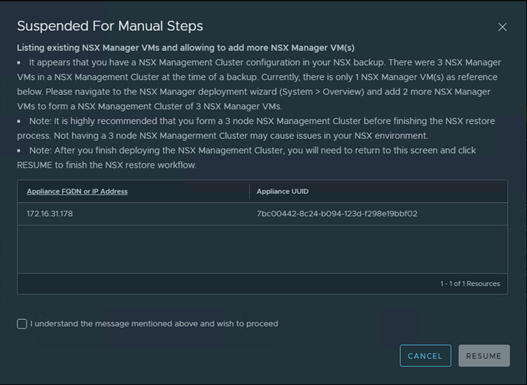
“It appears that you have a NSX Management Cluster configuration in your NSX backup. There were 3 NSX Manager VMs in a NSX Management Cluster at the time of a backup. Currently, there is only 1 NSX Manager VM(s) as reference below. Please navigate to the NSX Manager deployment wizard (System > Overview) and add 2 more NSX Manager VMs to form a NSX Management Cluster of 3 NSX Manager VMs.”
Since we had 3 NSX-T managers on the primary site, backup is prompting us to install remaining 2 nsx-t managers before the restore can be proceed.
Note: After you finish deploying the NSX Management Cluster, you will need to return to this screen and click RESUME to finish the NSX restore workflow.
Before you install an additional nsx-t mangers, make sure to set the VIP of the cluster to new ip address…
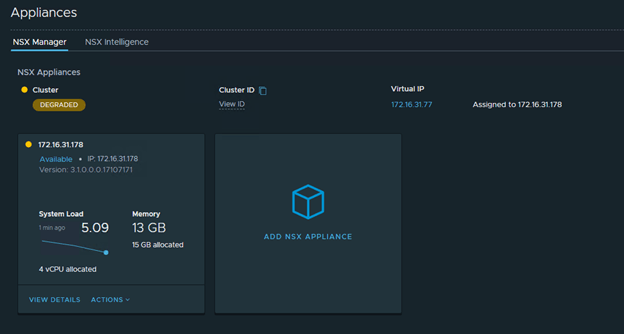
Change the VIP from 172.16.31.77 to 172.16.31.177…
It will take around 10 mins to bring back services and to be able to access new VIP.
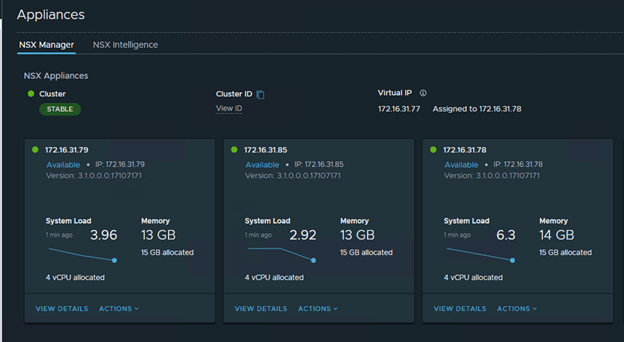
Deploy the 2nd nsx-t manager once the VIP is accessible. And then followed by 3rd NSX-T manager. Please note that the Cluster Status shows as ‘Degraded’ in the entire process.
Login to the VIP once it is up and running.
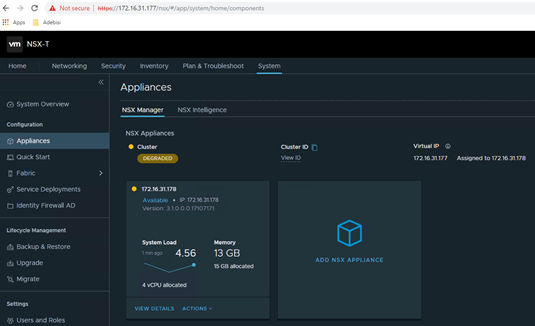
Next, we deploy an additional NSX-T managers.

On the next page, Compute Managers were not listing. Cancelled the wizard and checked compute managers. It shows as ‘Down’
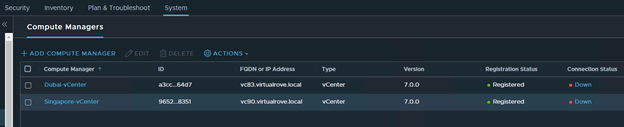
Click on ‘Down’ to check the error msg.
“Plugin for compute manager is not running.”
And ‘Resolve’ option was grayed out. Looks like something wrong with the vCenter Server Extensions. Anyways, since it is a lab env, I would not worry much to deploy an additional NSX-T manager. However, we did not receive this error while doing the production DR at customer site.
Let’s go back to backup and resume the operation.

The restore process moved to 62%…

Next, It prompts to check the CM/VC connectivity. (Compute Managers / vCenter). We move on by clicking Resume here.

Then the backup process stops again and prompt to check all listed fabric node connectivity. We can ignore this, since it says that, ‘These nodes might eventually discover the NSX Manager’

Restore process continues to 96%

And finally restore was successful. 😊
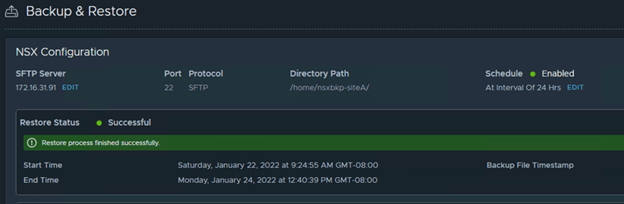
Logout and re-login to NSX-T VIP. You should see a msg.

However, it does stop here. We need to make sure that all nodes are connected to new NSX-T manager. You can also deploy an additional NSX-T mangers if needed at this stage, however I skipped it due to compute capacity in the lab.
Couple of tasks after the Restore process…
Navigating to host transport node, it shows couple of error and the same time it gives an option to ‘Resolve’ it.
One of the compute managers shows ‘Down’. Let’s try Resolve option.
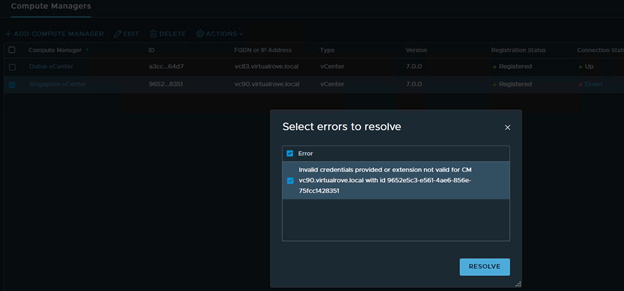
It’s UP now.

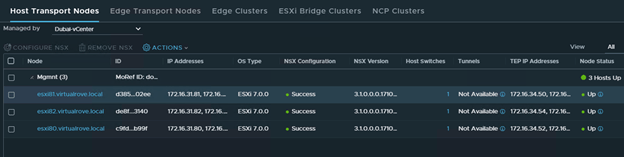
Dubai-vCenter transport nodes are UP.

Singapore-vCenter transport nodes are UP.
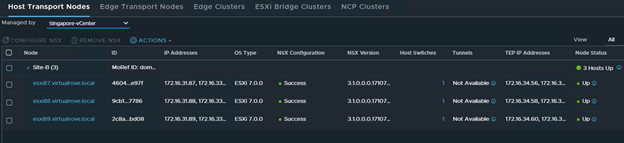
In an actual DR scenario, primary site (Dubai) will show as down since the site itself went down and that’s when we started this restore process.
Edge transport node shows ‘Failed’
Host configuration: Failed to send the HostConfig message.

Surprisingly, putting the edge node in ‘NSX Maintenance Mode’ and Existing from it resolved the error.

We had to reboot all EDGE VM’s at customer location to resolve this issue.
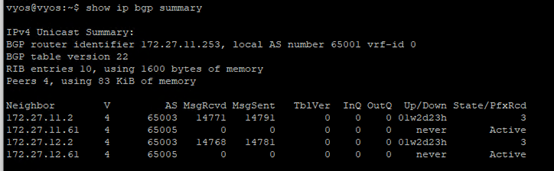
Let’s check the BGP routes on the TOR.
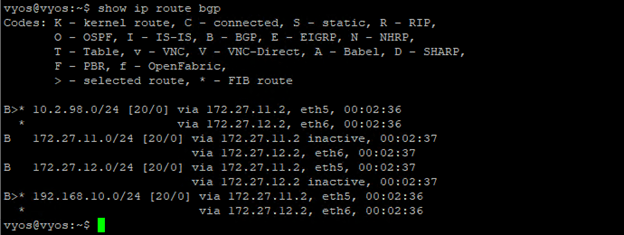
All looks good here.
The DATA plane did not get affected in this entire activity at all. All workload VM’s had connectivity to the TOR.
Note: vMotion of any VM as well as Snapshot revert or any network related changes to VM will end up losing connectivity to the VM until NSX-T mangers are up & running.
Next, We had already verified routing. For testing purpose, we moved couple of test VM’s from primary site to dr site and it was all good. All newly connected VM’s were able to reach TOR. To move the workload from SiteA to SiteB, customer can opt for SRM (Site Recovery Manager) or any third party VMware compatible product.
We have successfully restored NSX-T manager on the DR site. The entire activity took 2.5 hours at the customer site. You will definitely face multiple issues while performing the DR and it is difficult to get this to success level at first run. At the same, you really don’t want to get used to this DR process. 😀
Thank you for reading the post. I hope this post has added some value to perform successful DR. Good Luck. Leave your comments if you face any issues and I should be able to give you some inputs.
Are you looking out for a lab to practice VMware products…? If yes, then click here to know more about our Lab-as-a-Service (LaaS).
Leave your email address in box below to receive notification on my new blogs.