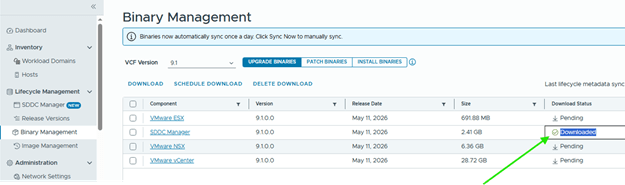
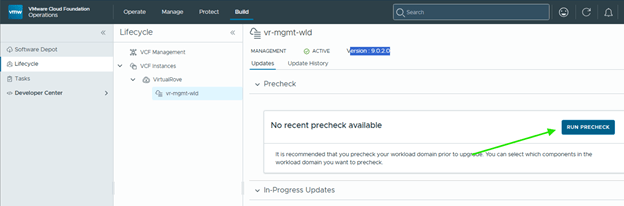
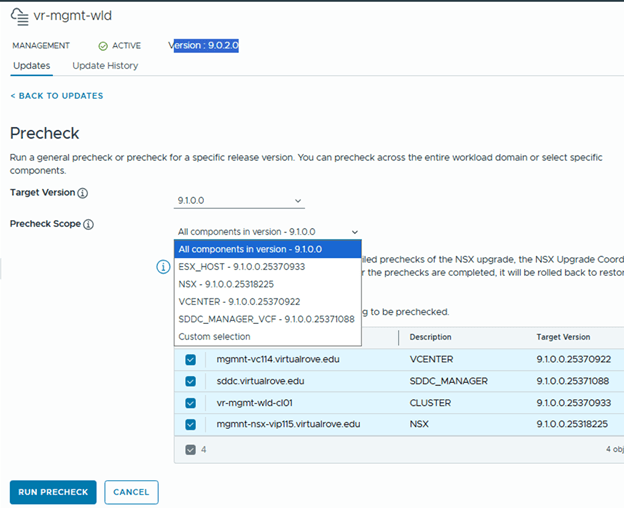
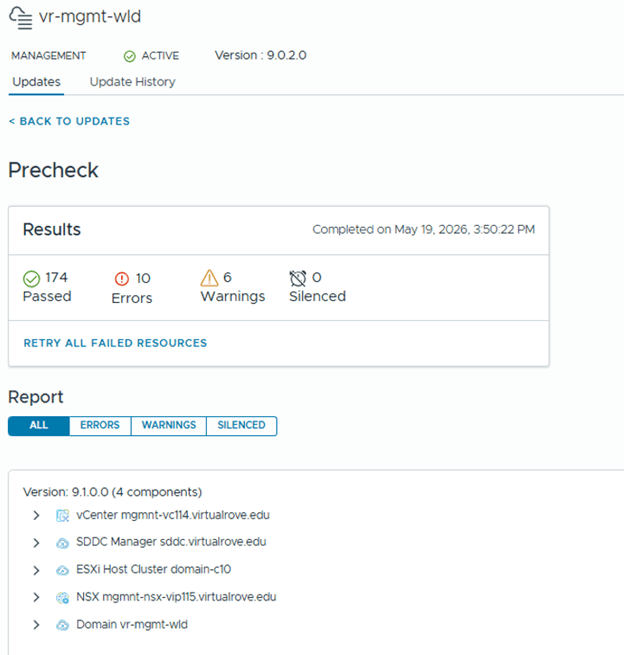
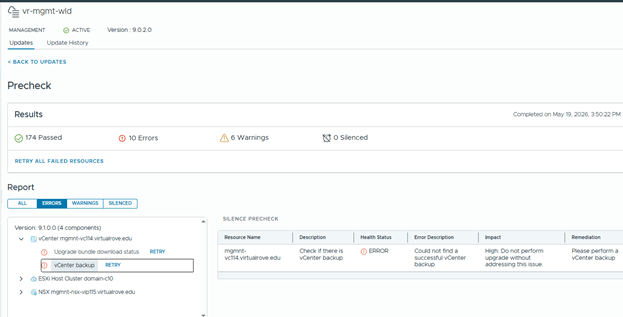
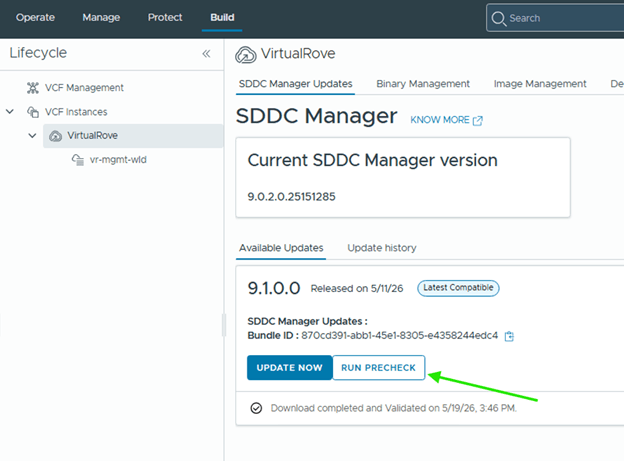
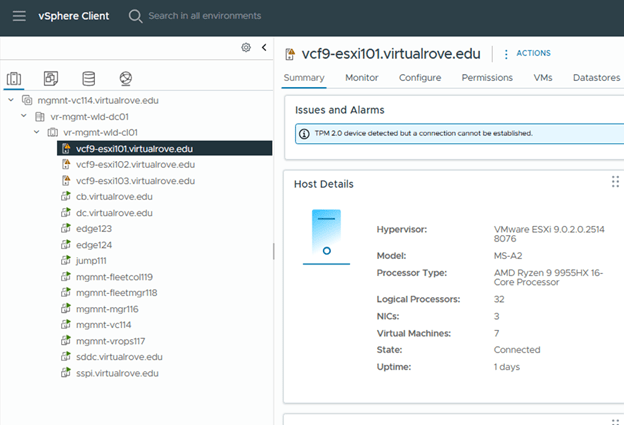
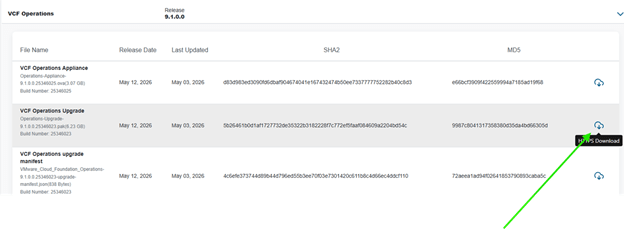
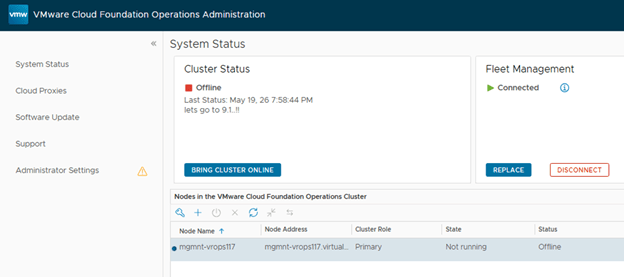
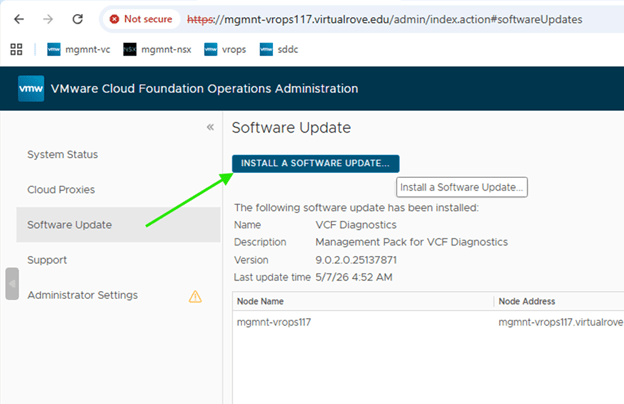
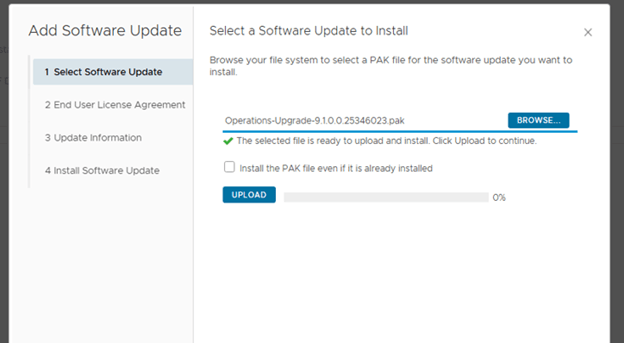
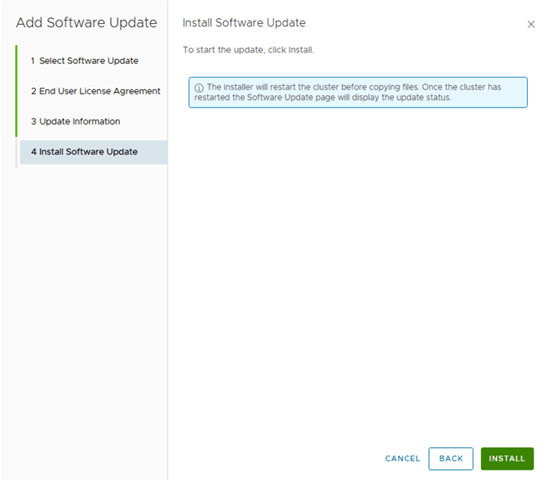
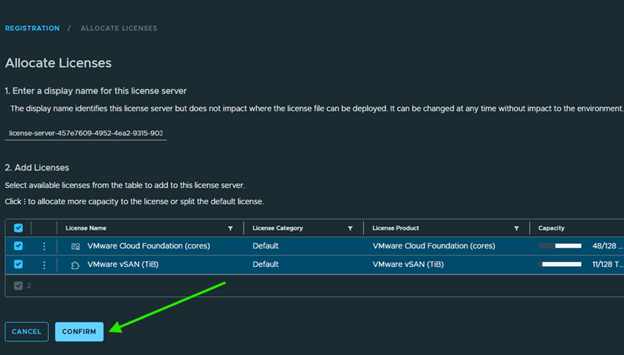
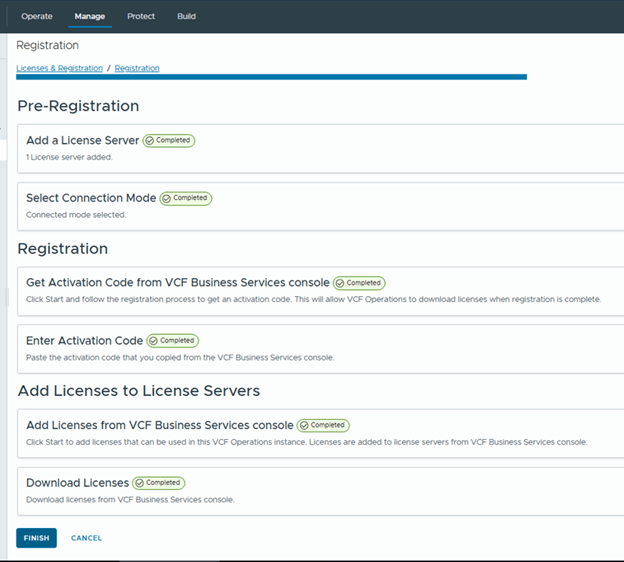
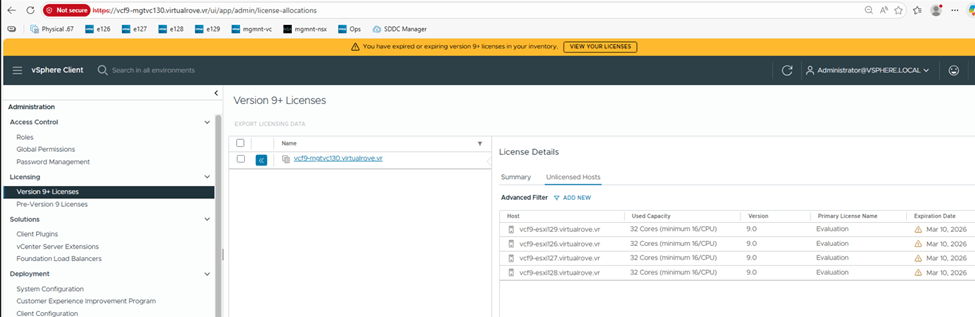
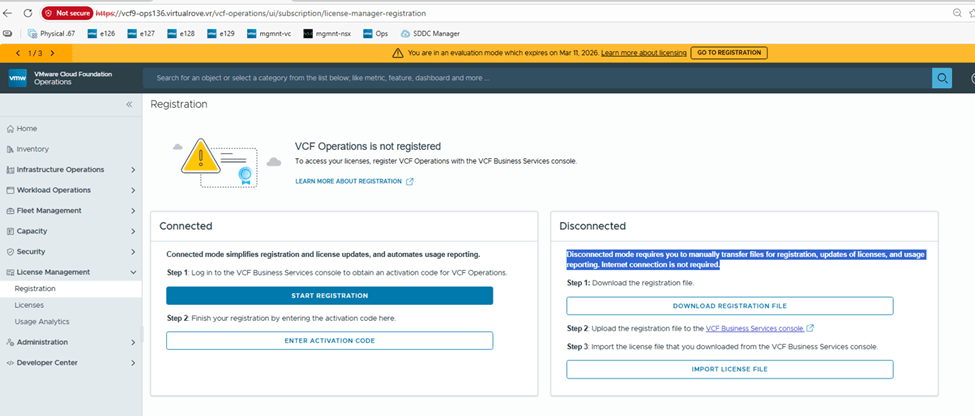
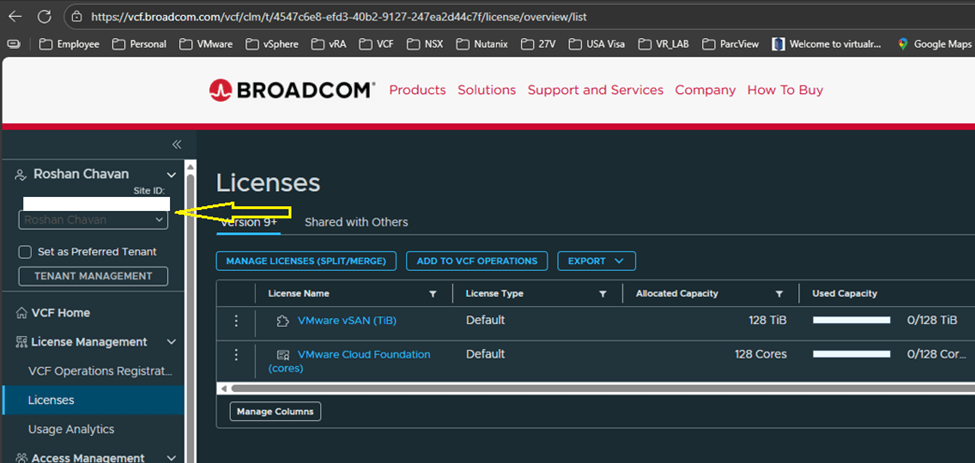
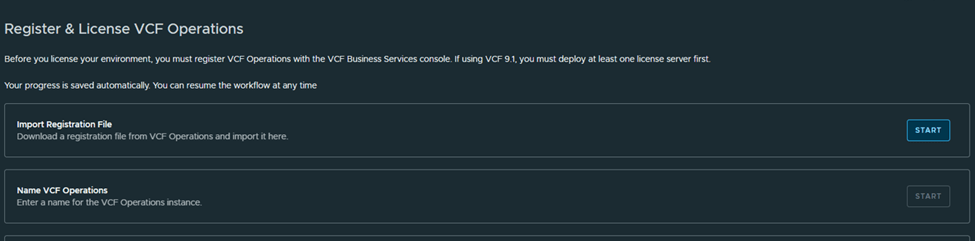
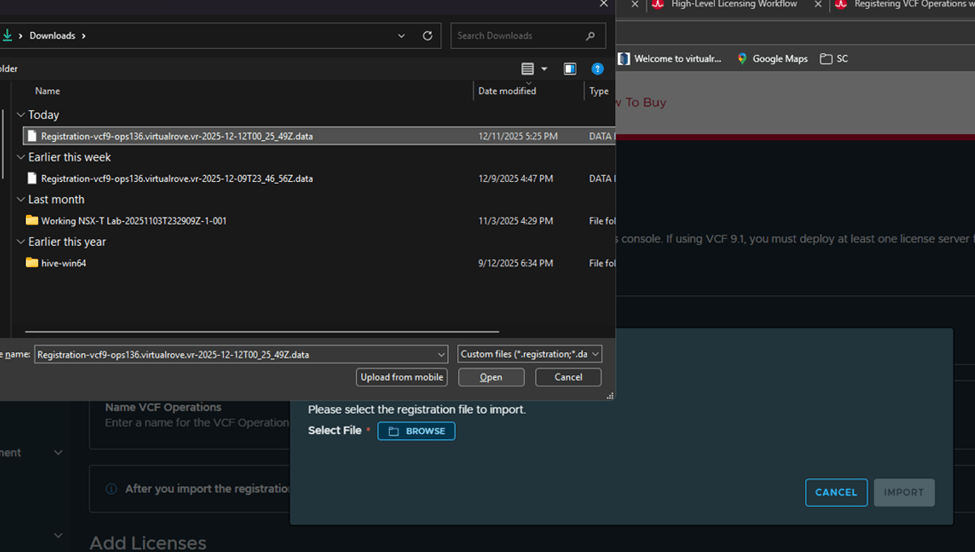
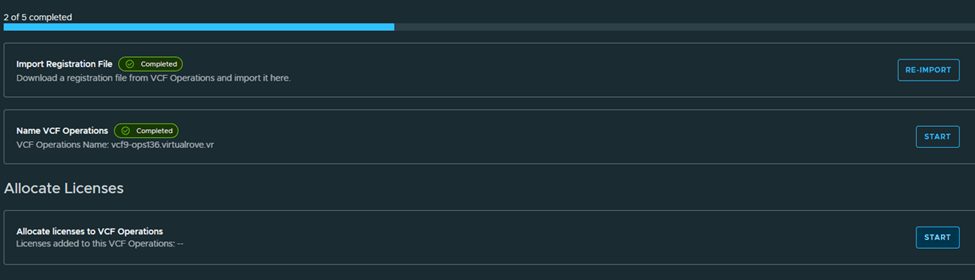
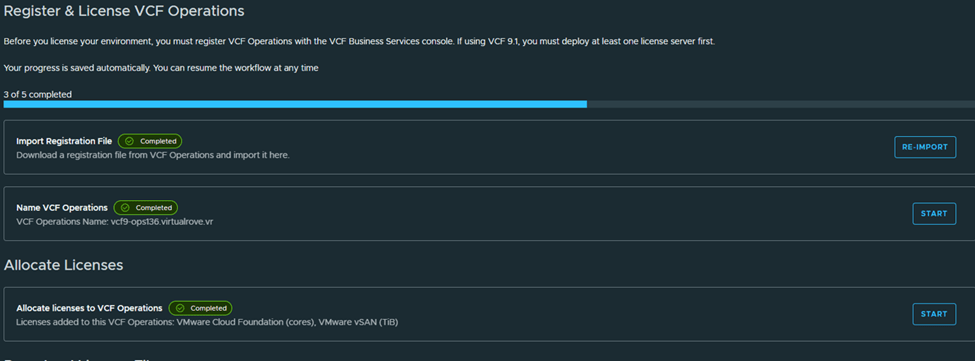
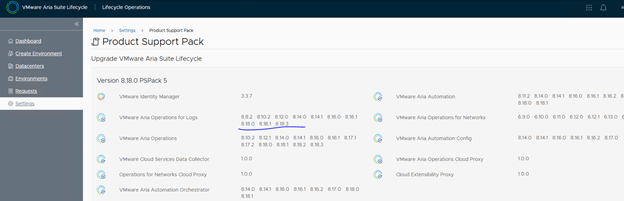
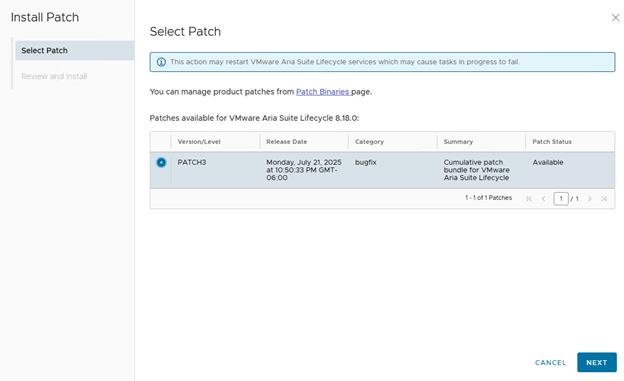
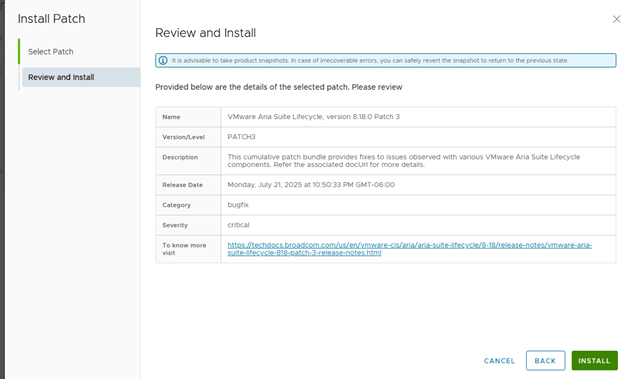
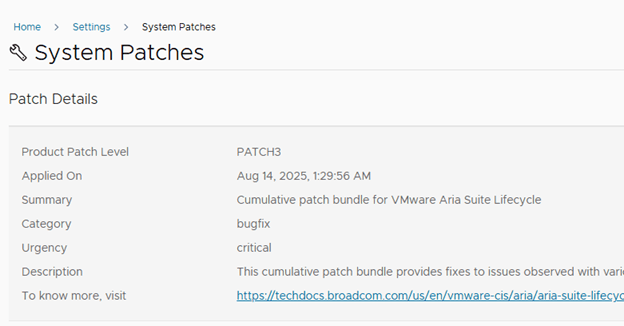
Step 6: Upgrade NSX Manager
Run NSX upgrade prechecks and resolve any reported issue before starting the upgrade.
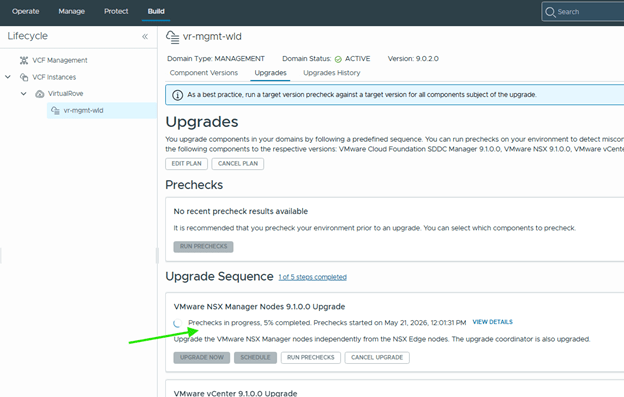
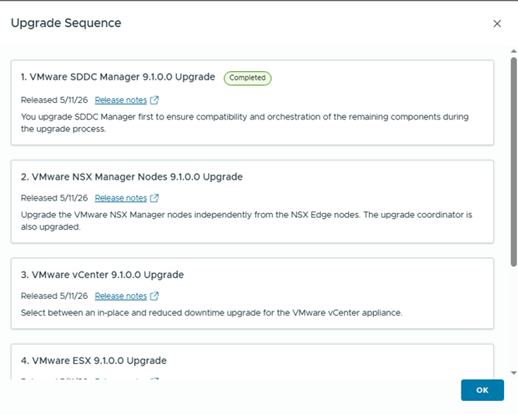
You can also check high level upgrade sequence,
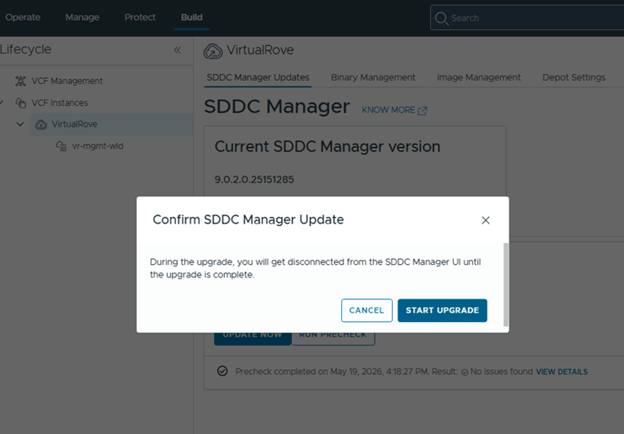
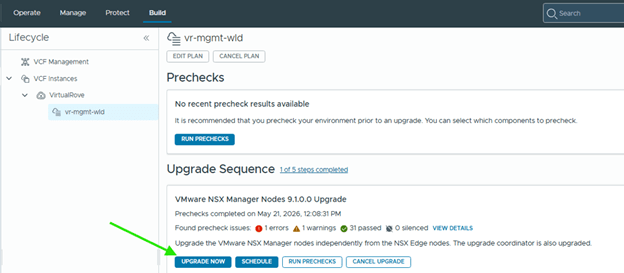
Once all prechecks completes, you can start the upgrade or schedule it,
Important: You may not see the NSX version fully reflected immediately after the NSX Manager upgrade. NSX is not considered fully upgraded until all ESX hosts in every vSphere cluster that shares the NSX Manager are upgraded to 9.x and the NSX finalize procedure completes.
However, the latest version can be seen on NSX Appliance page,
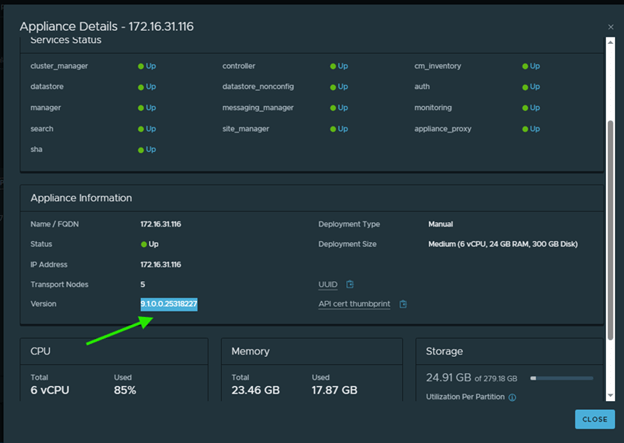
After NSX is upgraded, it disappears from the active upgrade list and the next component available for upgrade which is vCenter.
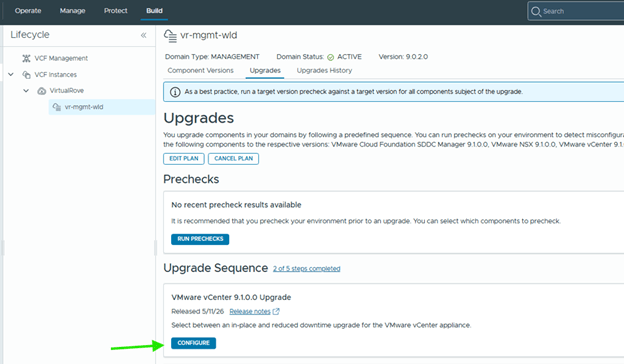
Step 7: Upgrade vCenter
The vCenter upgrade workflow provides two upgrade options.
vCenter Reduced Downtime Upgrade: This method uses a migration-based approach. In this approach, a new vCenter appliance is deployed and the current vCenter data and configuration is copied to it. During the preparation phase of a reduced downtime upgrade, the source vCenter instance and all resources remain online. The only downtime occurs when the source vCenter instance is stopped, the configuration is switched over to the target vCenter, and the services are started.
vCenter Regular Upgrade: Requires downtime of the vCenter instance during the entire upgrade process.
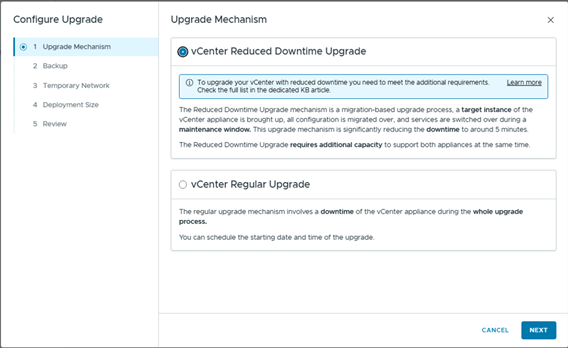
The reduced downtime method requires an additional temporary IP address from the VM Management subnet. Provide the required details and complete the wizard.
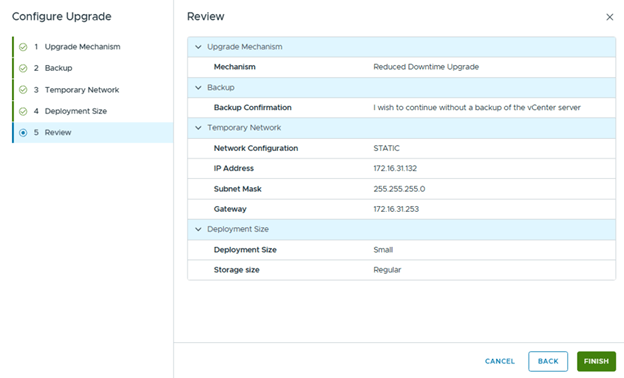
Completing this wizard prepares the upgrade configuration but does not immediately trigger the upgrade.
Return to VCF Operations to schedule the vCenter upgrade and cutover.
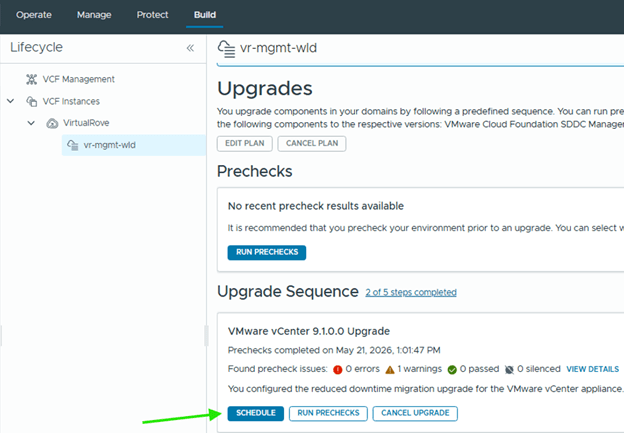
Choose appropriate options here,
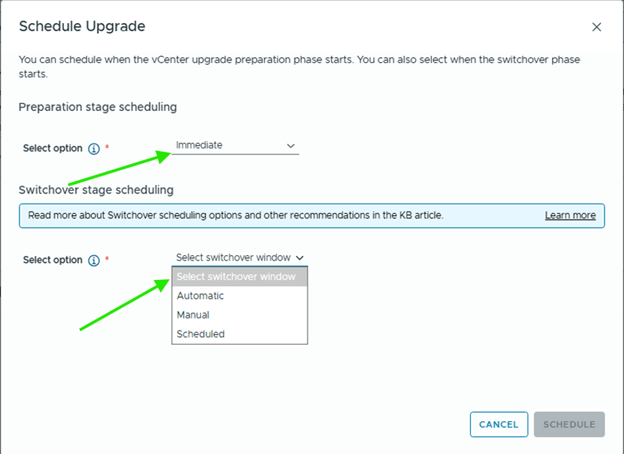
And schedule.
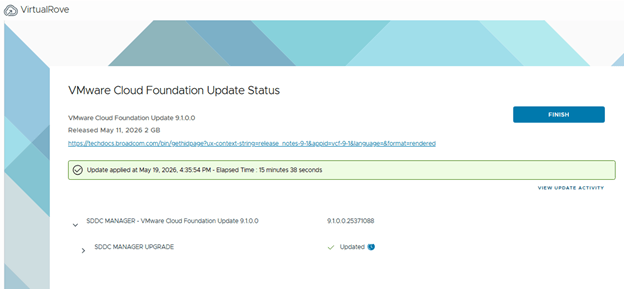
Upgrade status can be monitored,
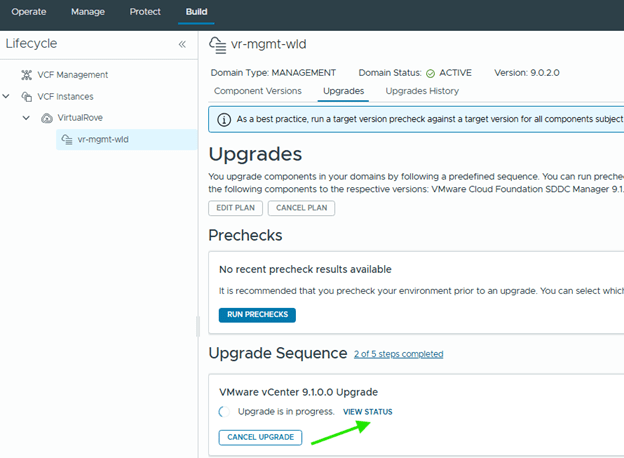
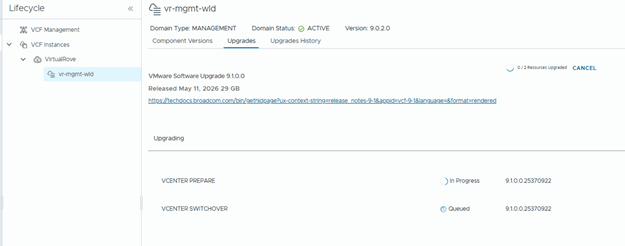
During the reduced downtime upgrade, a temporary vCenter appliance is created and data is migrated to it. After the workflow completes, review the upgrade sequence again to confirm the next available component.
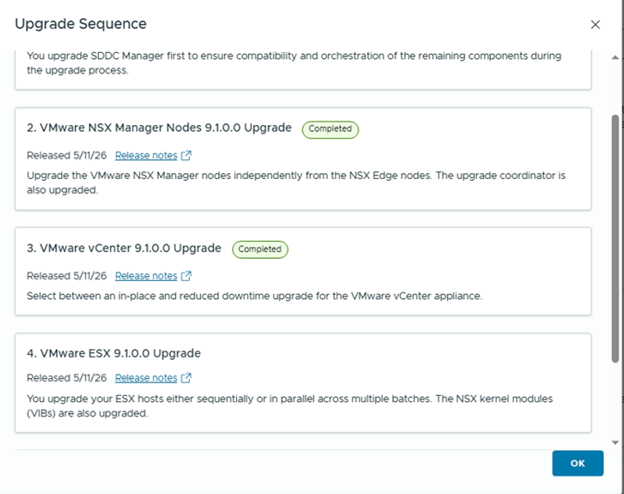
Step 8: Configure and Upgrade ESX Hosts
Before upgrading ESX hosts, create and assign the correct vSphere Lifecycle Manager image with the required ESX version and vendor add-ons.
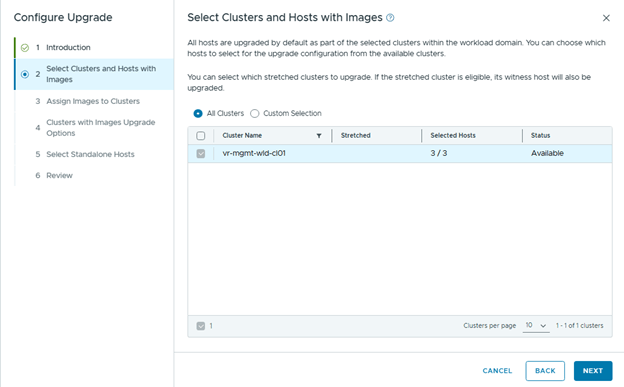
Create and assign the correct image with the target ESX version and vendor add-ons.
Login to MGMNT vCenter> Lifecycle Manager> Create New Image,
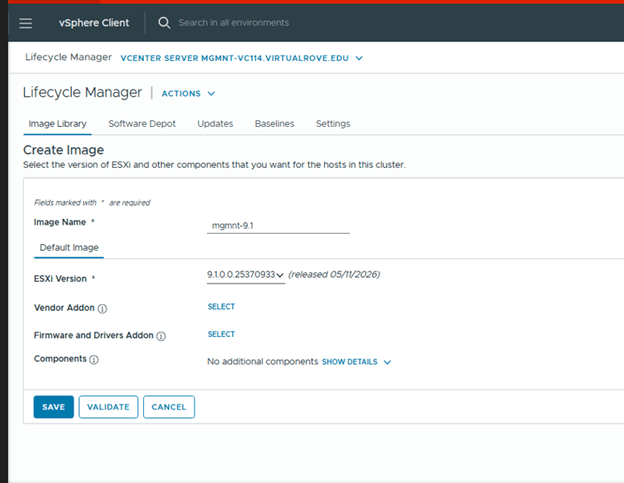
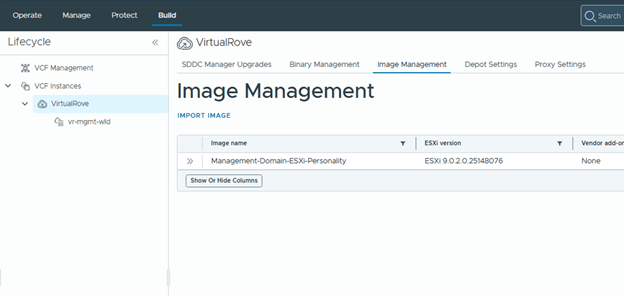
Then import the newly created image into VCF Operations.
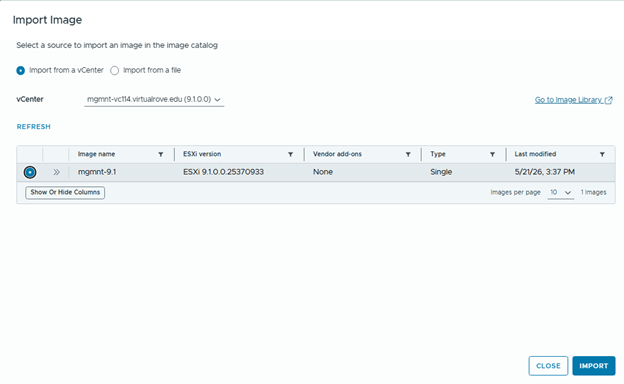
Assign the newly created image in “configure upgrade” wizard,
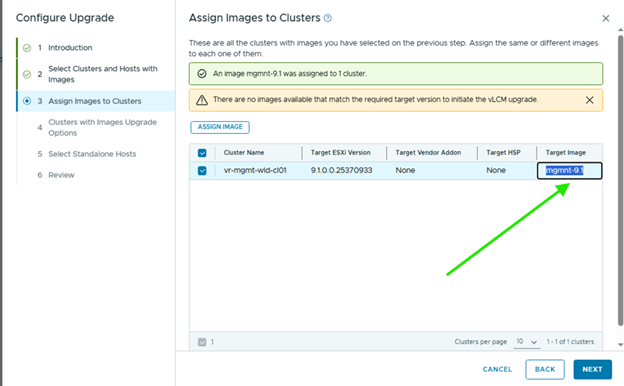
Choose the appropriate upgrade options. In my lab, I selected the sequential upgrade option.
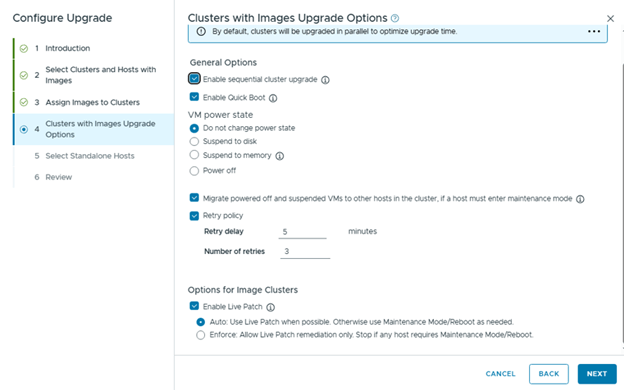
Review and Finish,
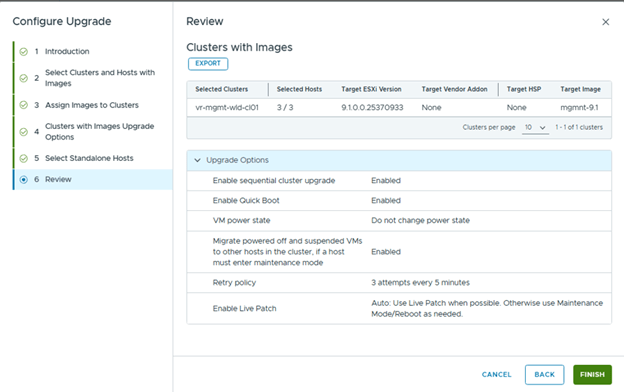
Then you can schedule or immediate upgrade from the upgrade page,
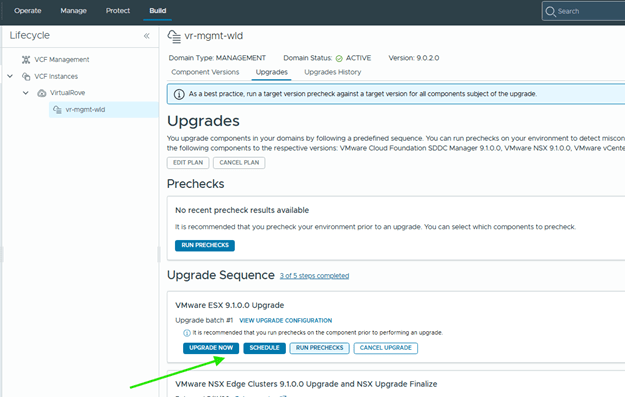
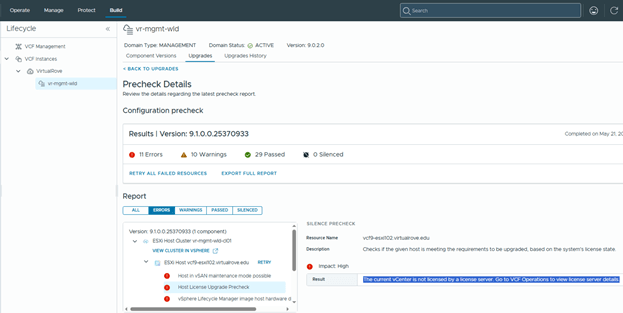
Got an error here in prechecks,
“Error – The current vCenter is not licensed by a license server.”
I’ve put together a short blog post on it,
VCF Upgrade Precheck Error: vCenter Is Not Licensed by a License Server
Back to upgrade process and hit upgrade for esxi,
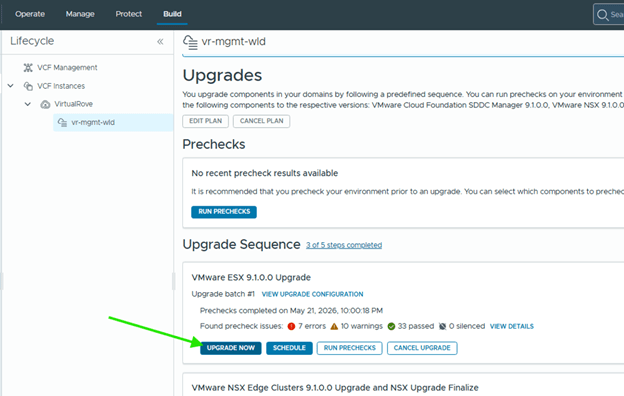
Monitor the status,
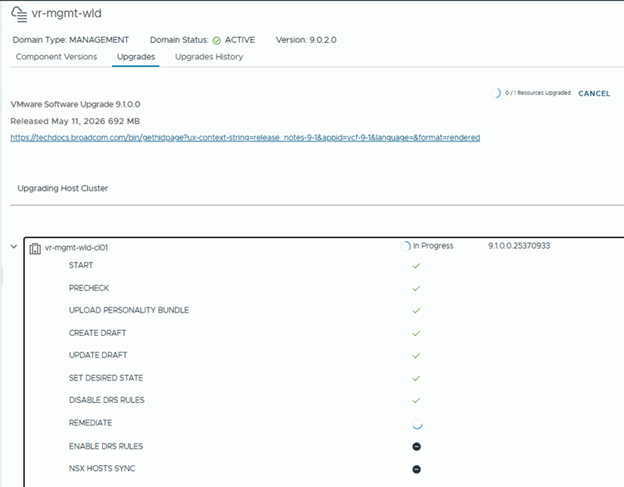
At a high level, each ESX host enters maintenance mode, virtual machines are migrated to other hosts, and the host is upgraded before moving to the next host.
After the workflow completes, all ESX hosts are upgraded to version 9.1.
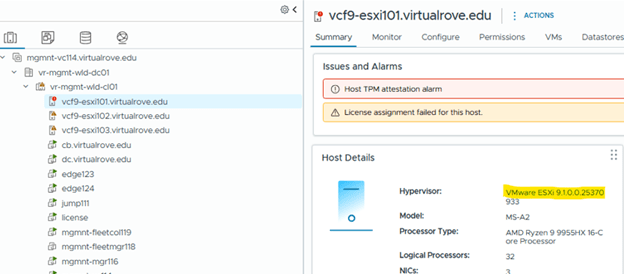
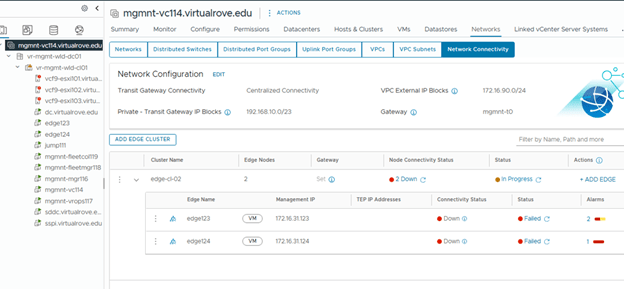
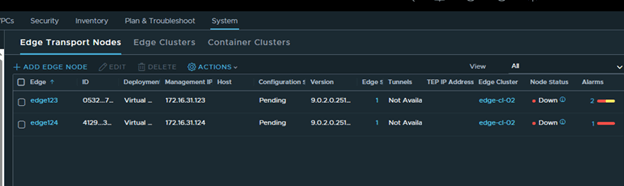
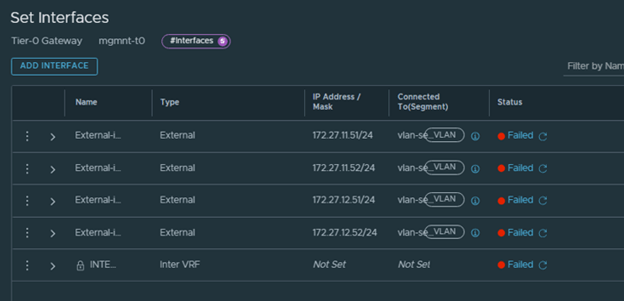
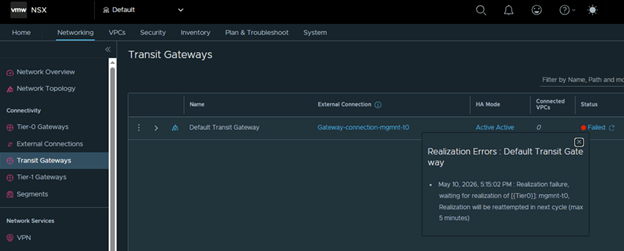
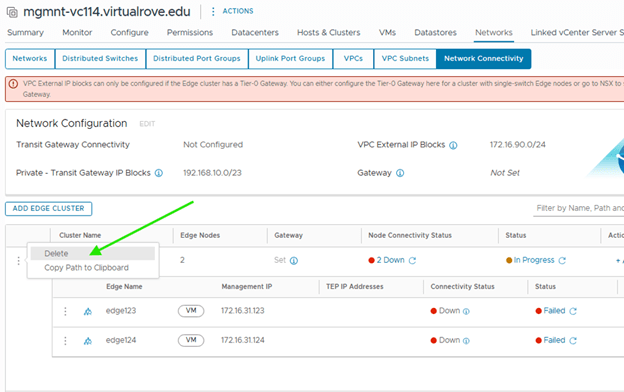
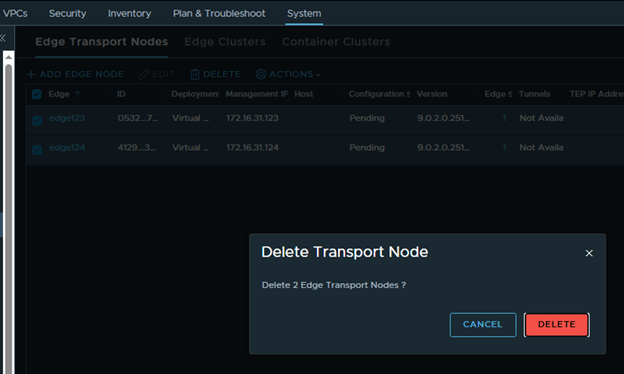
Step 9: Upgrade Edge Clusters
The final lifecycle step is to upgrade the NSX Edge clusters in the environment.
Click on Configure,
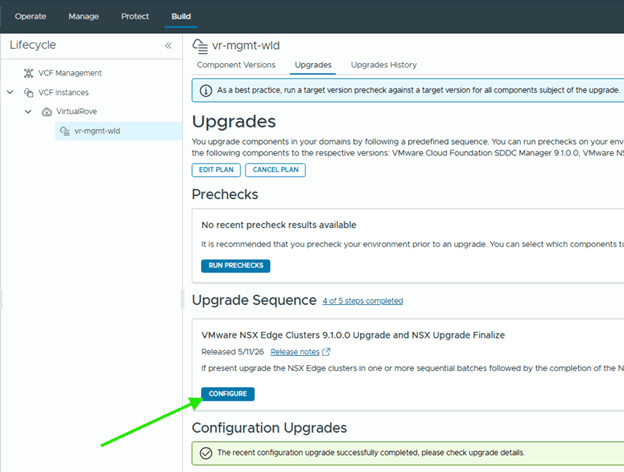
My lab environment does not have any Edge clusters, so I proceeded through the workflow and completed the step.
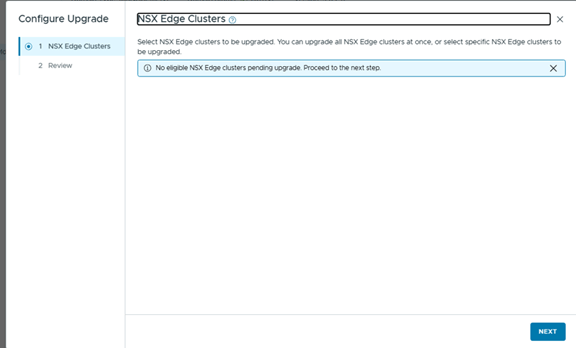
Click Upgrade on last step,
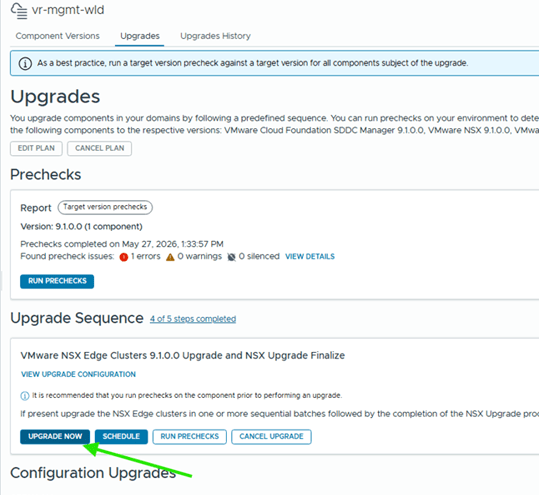
Upgrade Complete
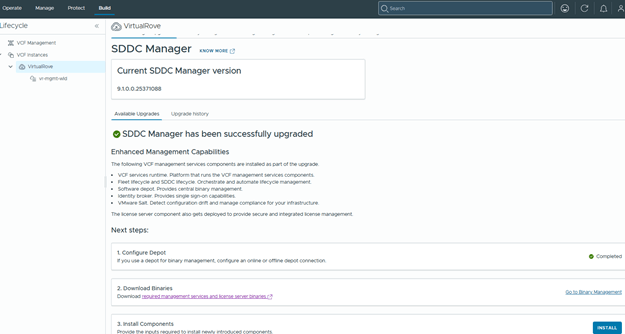
At this point, the management domain upgrade from VCF 9.0.2 to VCF 9.1 is complete.
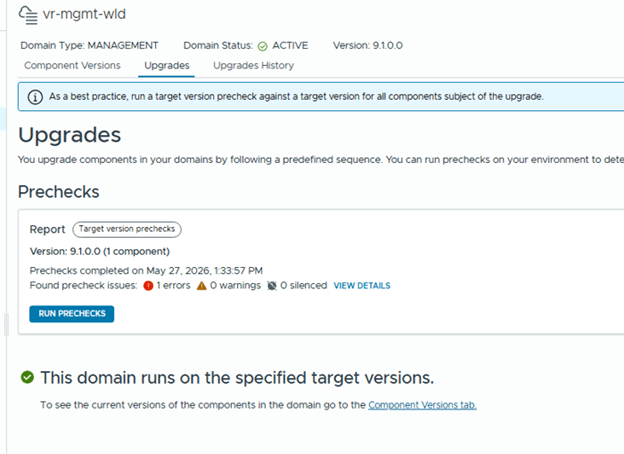
As a final validation, review the Component Versions tab and confirm that all upgraded components report the expected VCF 9.1 versions.
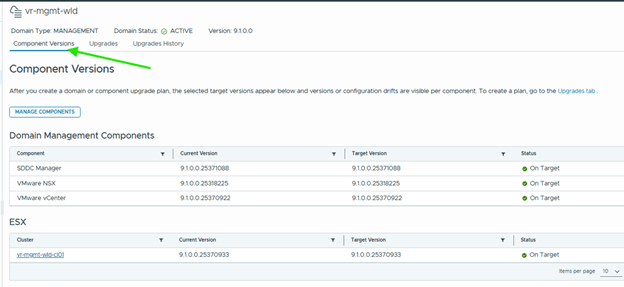
After the management domain is upgraded, follow the same procedure for each workload domain in the environment.
Here is the official documentation link for an upgrade process,
Upgrading to VMware Cloud Foundation 9.1
Reminder: This blog covers the upgrade process from VCF version 9.0.2 to VCF 9.1. If you are upgrading from VCF 5.x to VCF 9.1, review the official documentation and supported upgrade path before starting.
The next and final blog in this series will cover post-upgrade validation checks after upgrading to VCF 9.1. Stay tuned.
Lessons Learned and Practical Notes
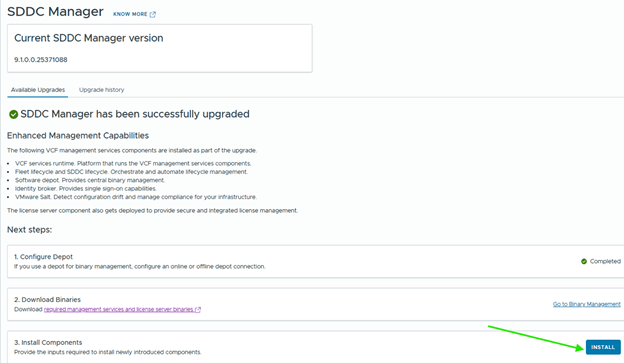
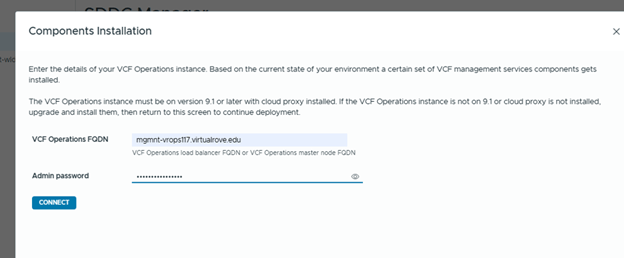
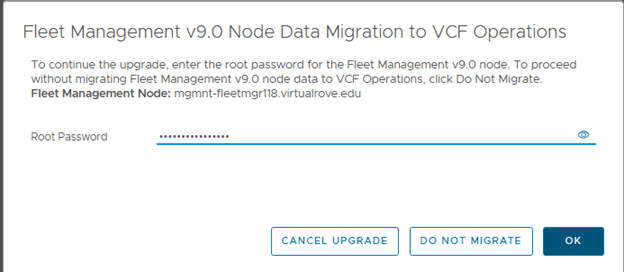
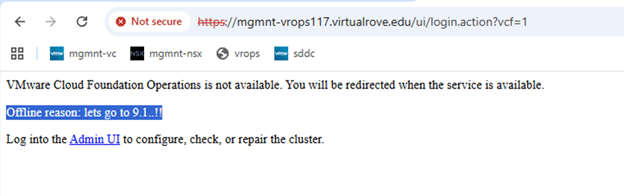
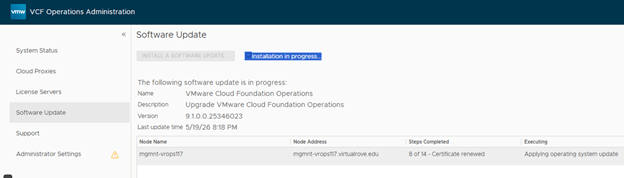
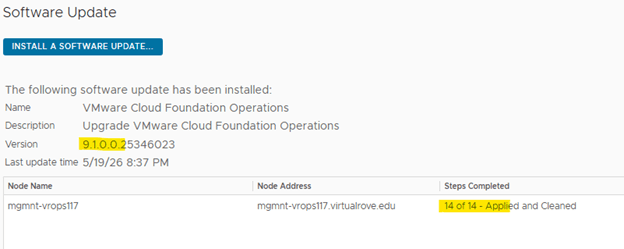
- The upgrade process automatically decommissions the standalone VCF Operations Fleet Management appliance. Fleet management capabilities move into the updated VCF Operations and management services architecture.
- VCF Identity Broker should be moved to the shared VM Management network before the upgrade if it is currently deployed on a different port group.
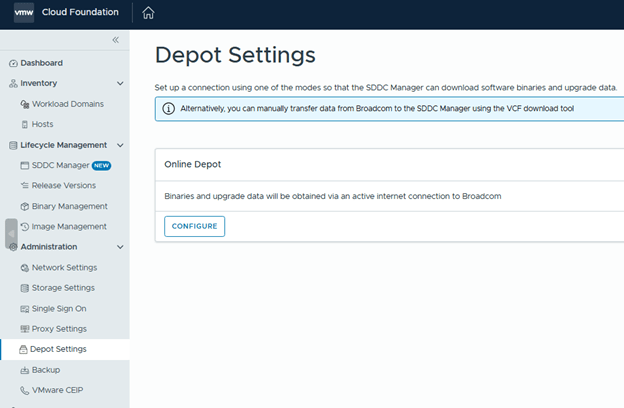
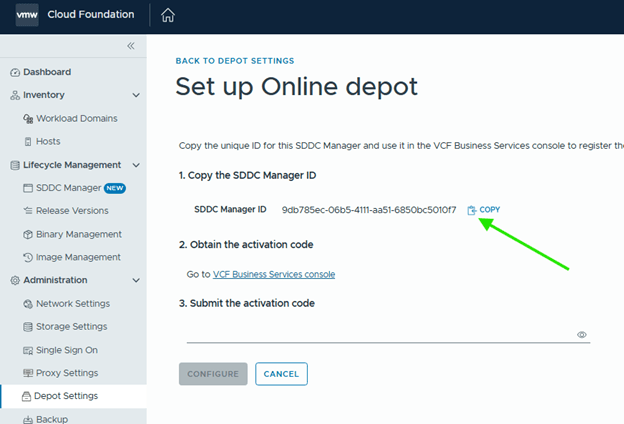
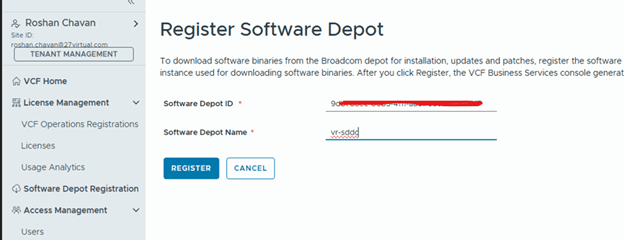
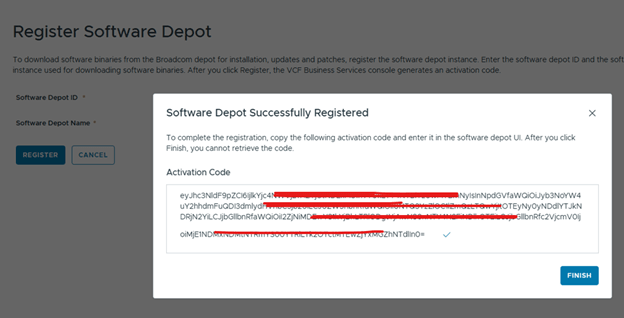
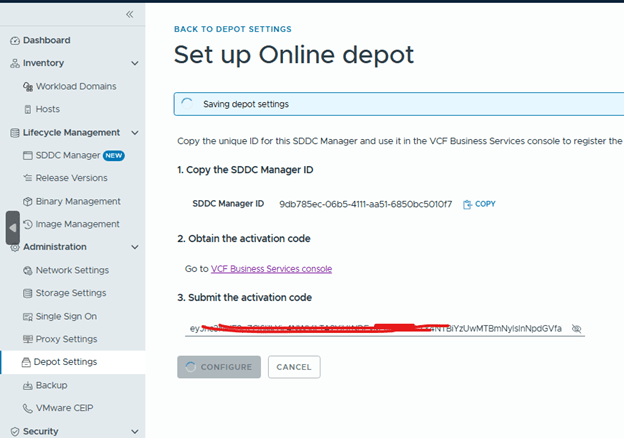
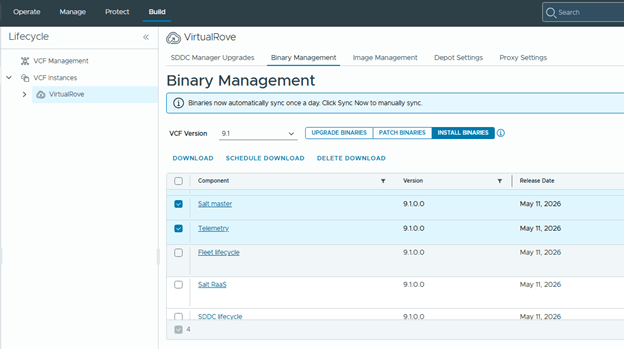
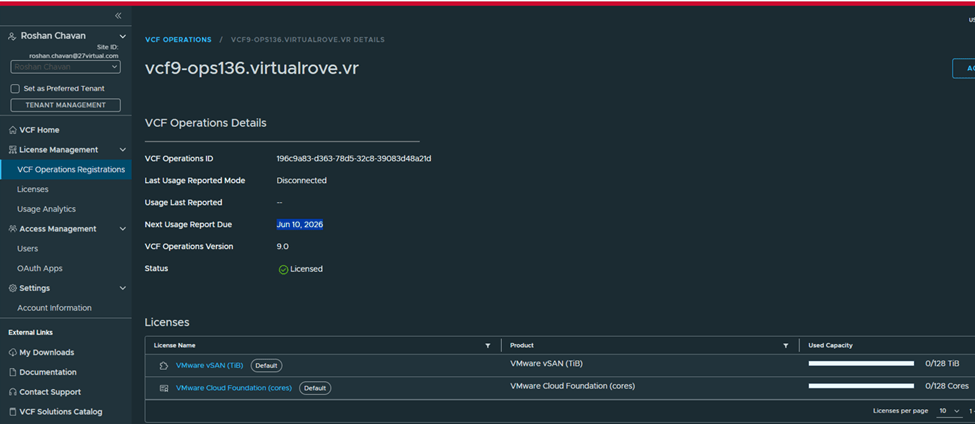
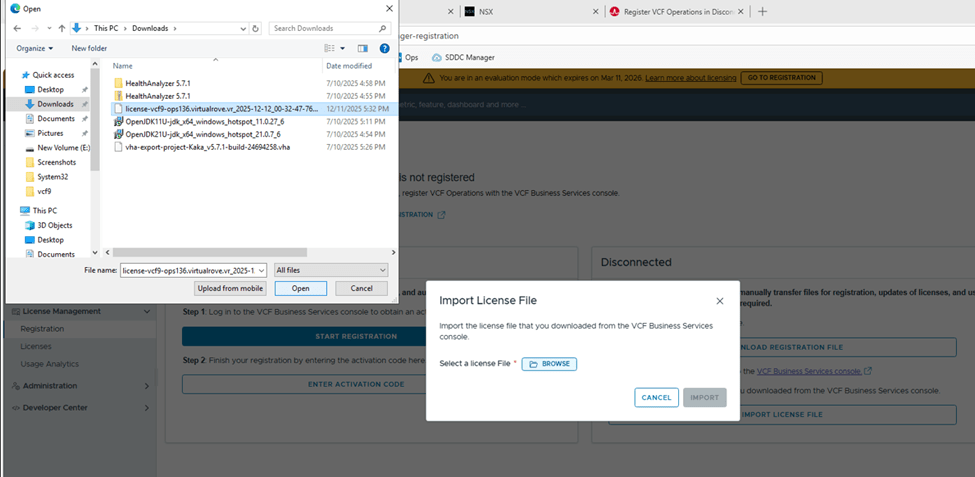
- After upgrading SDDC Manager to version 9.1, reconfigure the online or offline depot to use an activation code from the VCF Business Services console instead of a download token.
- Embedded VCF Identity Broker is automatically upgraded during the vCenter instance upgrade.
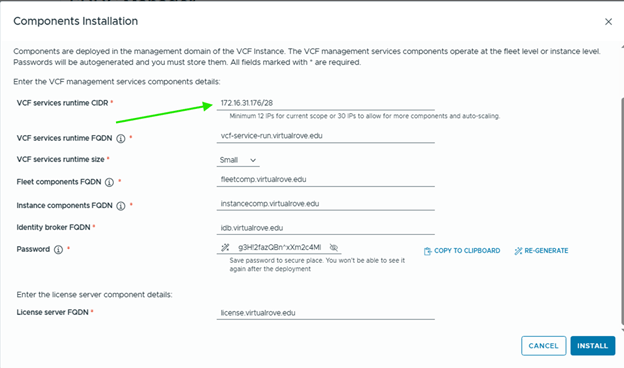
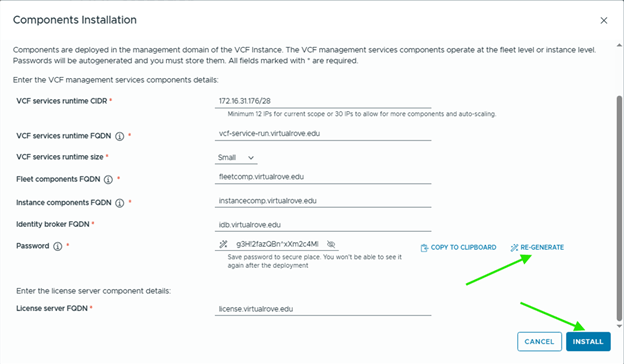
- You must provide a dedicated IP range for the VCF Services Runtime. A minimum of 12 IP addresses is required.
- After deployment, do not move the VCF management services VMs to a different resource pool or VM folder. If you move the VMs to a new resource pool or VM folder, subsequent patching, deployment, or scale out operations fail.
- If you have VCF Identity Broker 9.0.x, identity broker 9.1 deployment is skipped and you can later upgrade.
- Embedded VCF Identity Broker is automatically upgraded during the vCenter instance upgrade.
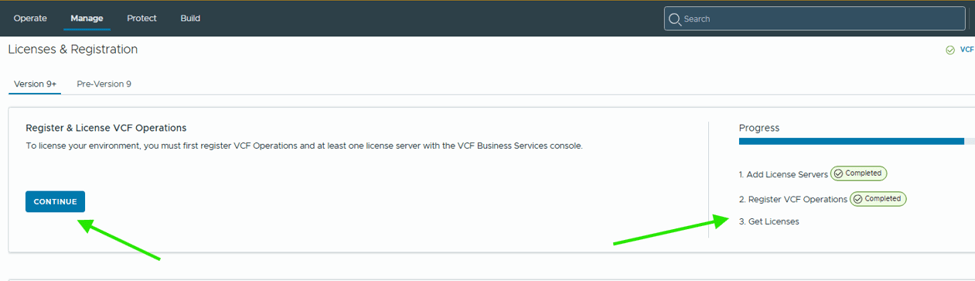
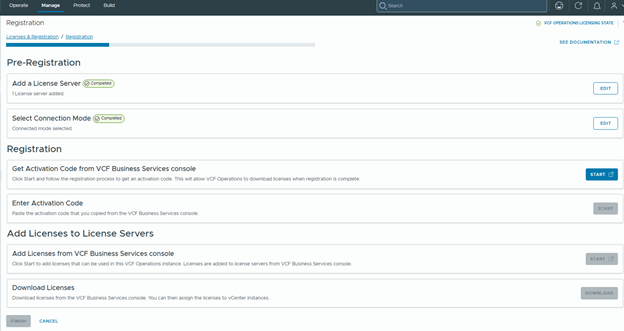
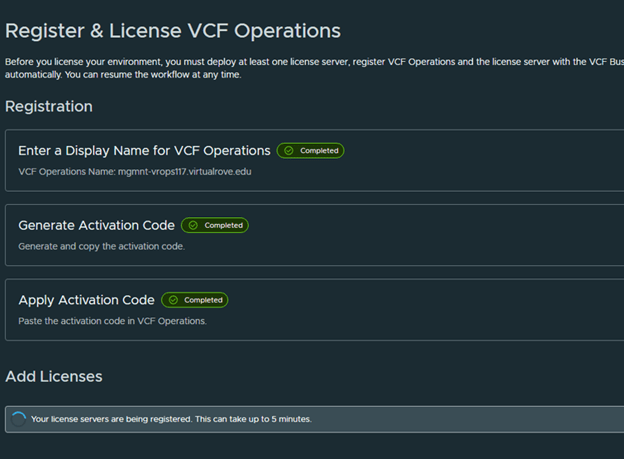
- After VCF management services are deployed, if VCF Operations is in connected mode, the license server is automatically registered and licenses are transferred to the license server.
Hope the content is helpful. Good luck with an upgrade. And post comments if you encounter new errors or if there are new lessons learned. Thank You.
Are you looking out for compute resources (CPU / Memory / Storage) to practice VMware products…? If yes, then click here to know more about our Lab-as-a-Service (LaaS).