We talked about registering VCF Operations on the Broadcom Portal and applying licenses to VCF Operations. Let’s continue and apply new licenses to vCenter and VSAN.
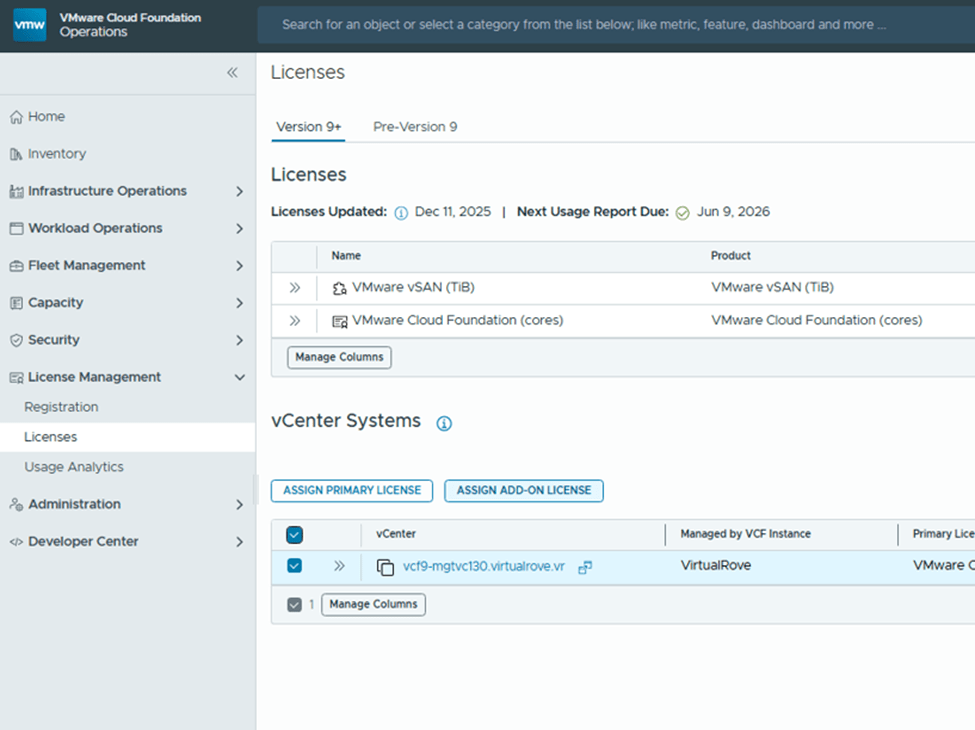
Click on Licenses> Assign Primary License
Select the VCF license and assign,
vCenter is fully licensed,
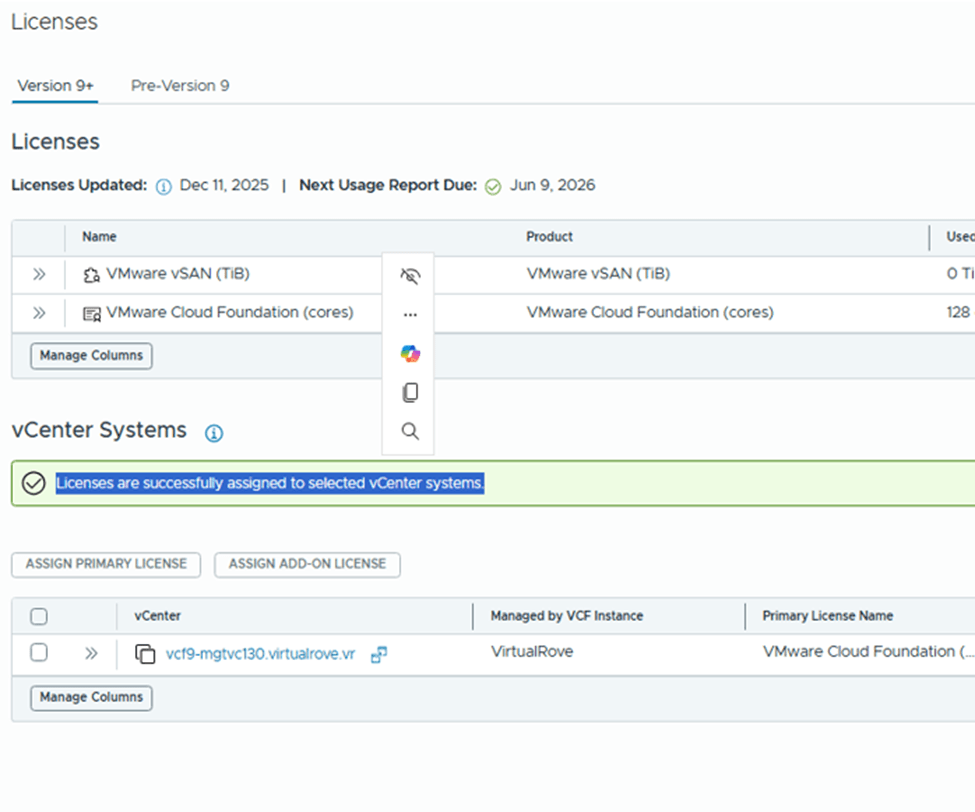
Back to licenses, Select vCenter and click on “Add-on license”
Select VSAN license and assign,
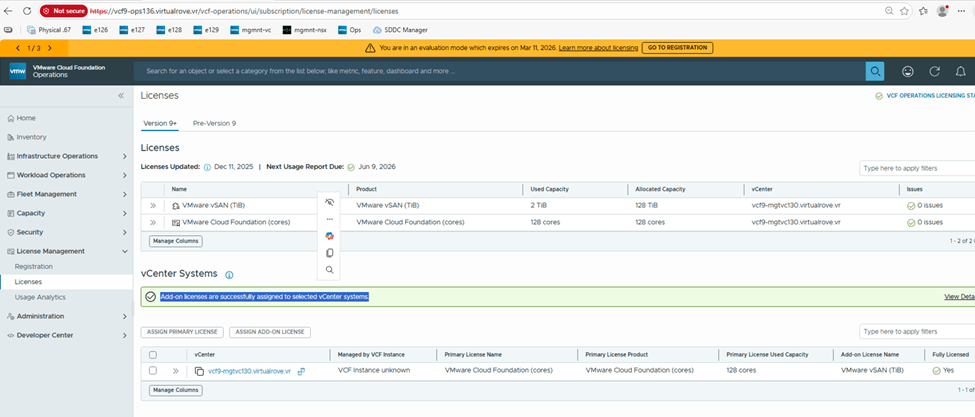
Add-on license applied successfully and vCenter is fully licensed,
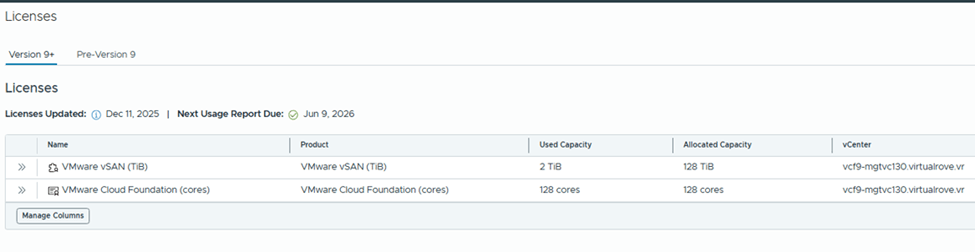
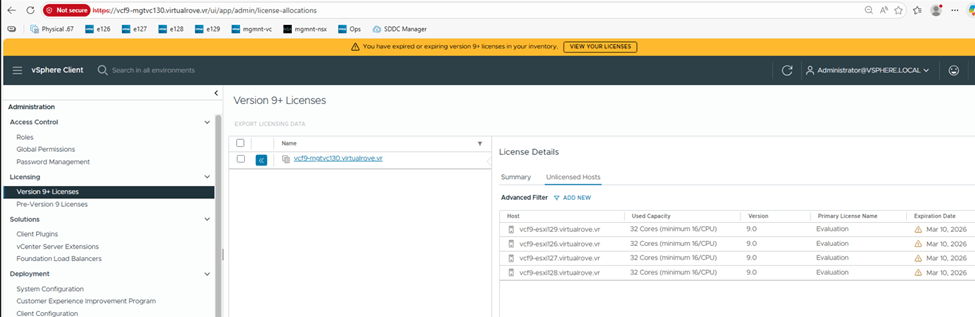
Check the “Used Capacity” in license section,
vCenter shows fully licensed,
Here is the link for official documentation on VCF 9 licensing,
That’s it for this post. We have licensed entire VCF 9 environment. Please refer to official documentation & make sure to update license usage every 180 days. 😊
Licenses are version-agnostic, eliminating version-based key mismatches
Managed centrally through VCF Operations and the VCF Business Services (VCFBS) portal
Designed for both connected mode (auto-reporting) and disconnected mode (manual uploads every 180 days)
Let’s dive deeper into it. I have freshly deployed VCF 9 environment.
After you deploy the env, it operates in evaluation mode for up to 90 days. During that period, you must license your environment.
Here are details for one of the esxi from the env,
As you can see, I have 2 physical sockets on this esxi and cores per socket are 4. That sums up to 8 CPU cores. However, when it comes to license calculation, it by default calculates 16 cores per socket even if I just have 4 cores per socket.
So, total number of licensed core on this esxi would be 32 cores.
I have 4 esxi hosts in this management workload domain cluster, so the total number of licensed cores would be (4*32) 128 cores.
Primary licenses apply only to ESXi hosts by count of physical CPU cores, with a 16-core minimum per CPU.
Moving to add-on license. This applies to vSAN Capacity in TiB’s. And the formula is, 1 TiB per licensed core. In my case, I will have 128 TiB allowed storage since I have 128 cores. For storage-heavy use cases, you need to purchase additional vSAN add-on capacity license.
Maintaining license compliance now includes periodic usage reporting: Connected Mode (Internet Connection Required): VCF Operations sends usage data automatically each day; updates required every 180 days
Disconnected Mode (Dark Site): Manually download, upload, and activate new license files every 180 days
Failure to report can place hosts into expired status—preventing workloads until remedied. Basically, all hosts gets disconnected and you cannot start any vm. ☹
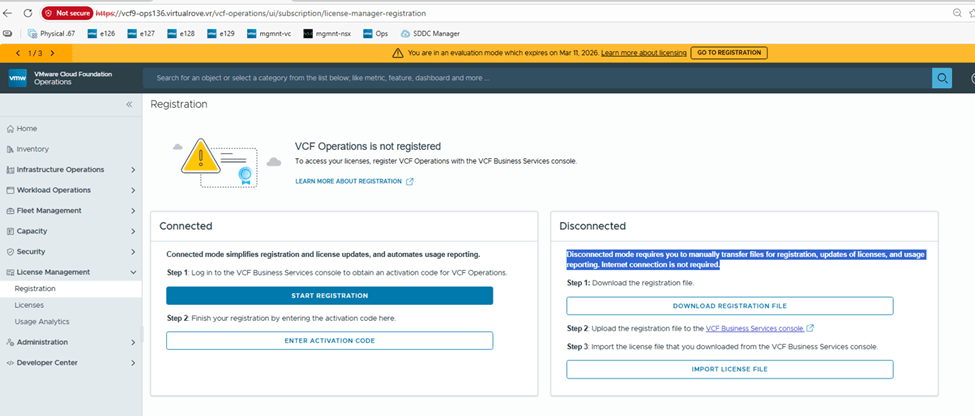
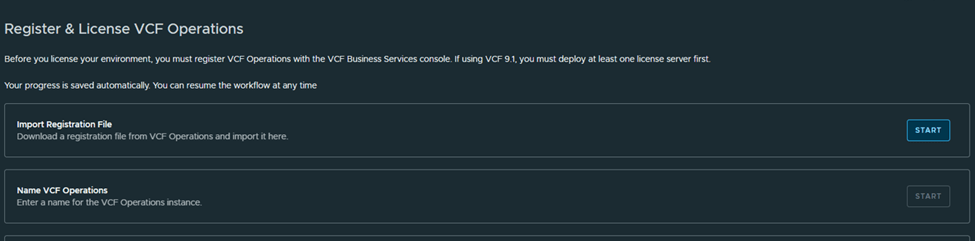
Let’s go to Ops> License Management> Registration
I will be demonstrating “Disconnected” mode for this blog.
Starting with version 9.0, the licensing model is the same for VCF and vSphere Foundation. You assign licenses only to vCenter instances. The other product components, including ESXi hosts, that are connected to the licensed vCenter instances, are licensed automatically.
You no longer license individual components such as NSX, HCX, VCF Automation, and so on. Instead, for VCF and vSphere Foundation, you have a single license capacity provided for that product.
For example, when you purchase a subscription for VCF, with the license you receive and assign to a vCenter instance, all components connected to that vCenter instance are licensed automatically.
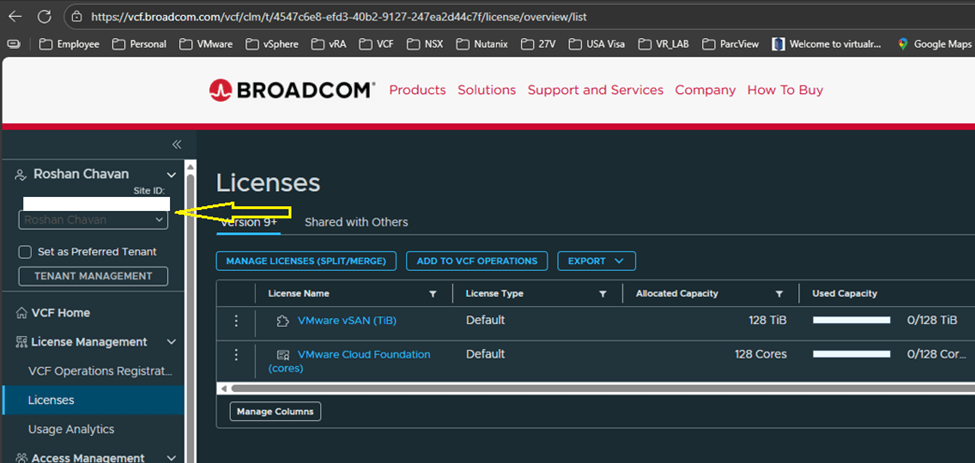
Switch the site ID and make sure it is correct one and click on License,
I have vmug licenses which are already showing up on the portal with my vmug entitlement.
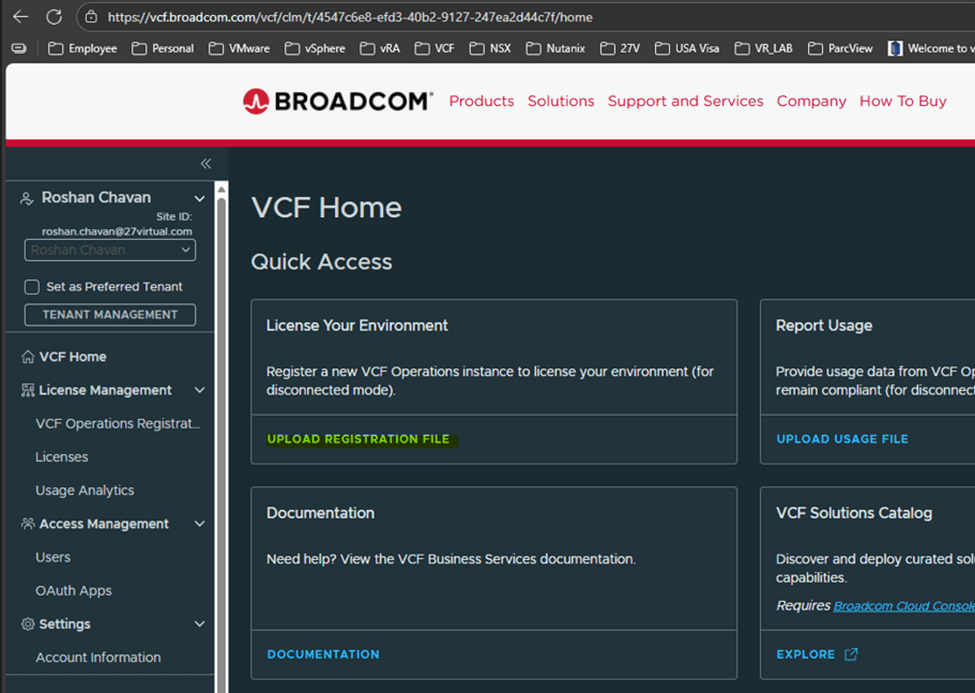
Back to VCF Home page on the portal, Click on “Upload registration file”
Upload the file that we downloaded earlier,
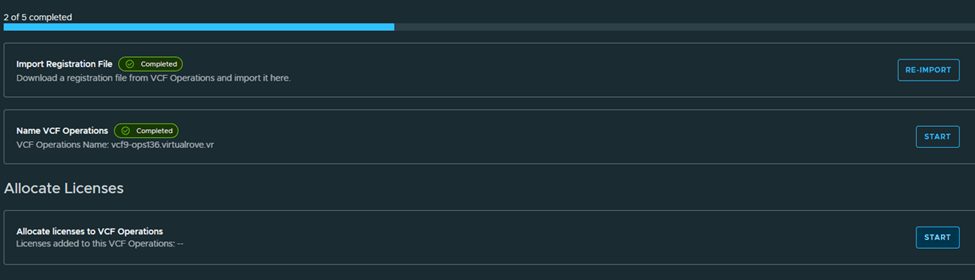
Next, Name the VCF Operations,
Next, Allocate licenses,
Next, Download the generated licensed file and mark as completed,
We are done on this portal here,
Back to registration page shows this,
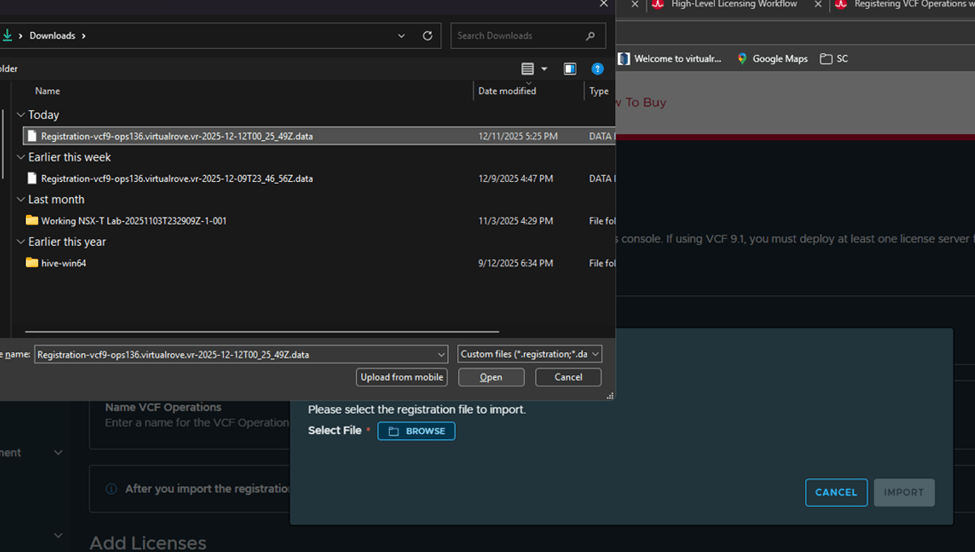
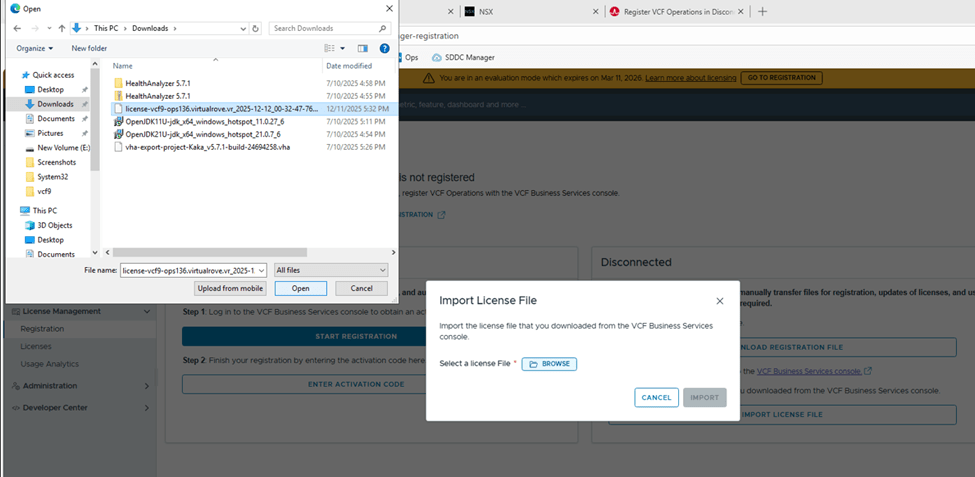
Let’s import the downloaded licensed file to our VCF operations in our environment,
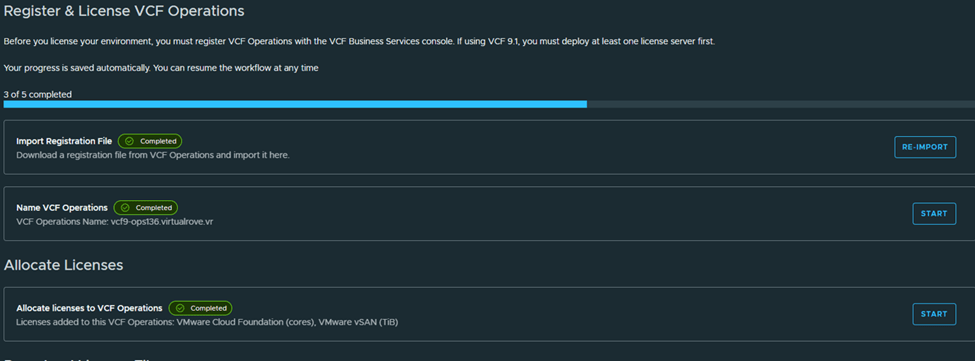
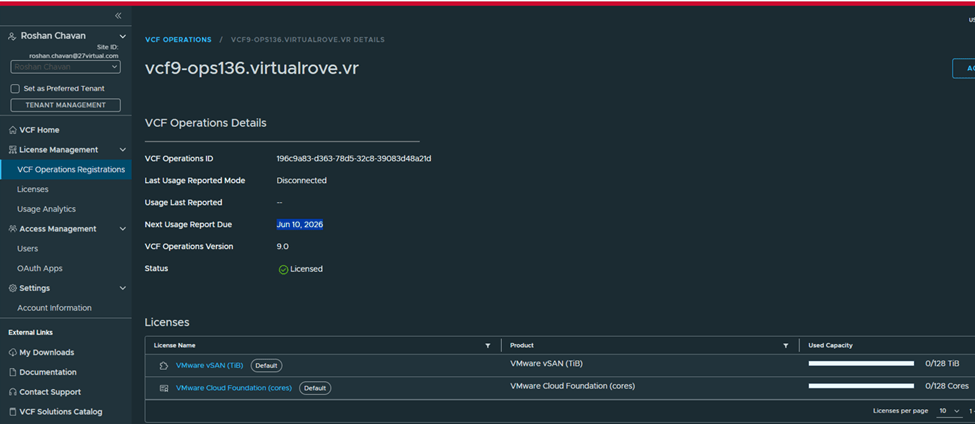
Once imported, VCF Operations shows registered,
Status: Licensed Mode: Disconnected Next usage date: You need to report license usage before this date, or else all hosts will be disconnected. VCF Operations name: shows Operations instance
We have licensed our VCF Operations instance. That’s a wrap for today! Stay tuned for the next blog—where we will talk about applying those licenses to vCenter and VSAN.
To manage the lifecycle of VCF fleet level Management components such as VCF Operations, VCF Operations for networks, VCF Operations for logs, VCF Automation & VCF Identity Broker, you need to use VCF Operations fleet management appliance. And before you can perform any of these operations, VCF Operations needs to be configured either for Online or Offline depot. This is the place where all downloaded binaries will be stored, which allows you to install, upgrade or patch any of the above-mentioned components.
Let’s dive into the lab, I have freshly installed VCF 9.0 env. Plan is to install further components in the lab,
VCF Operations> Fleet Management> Lifecycle
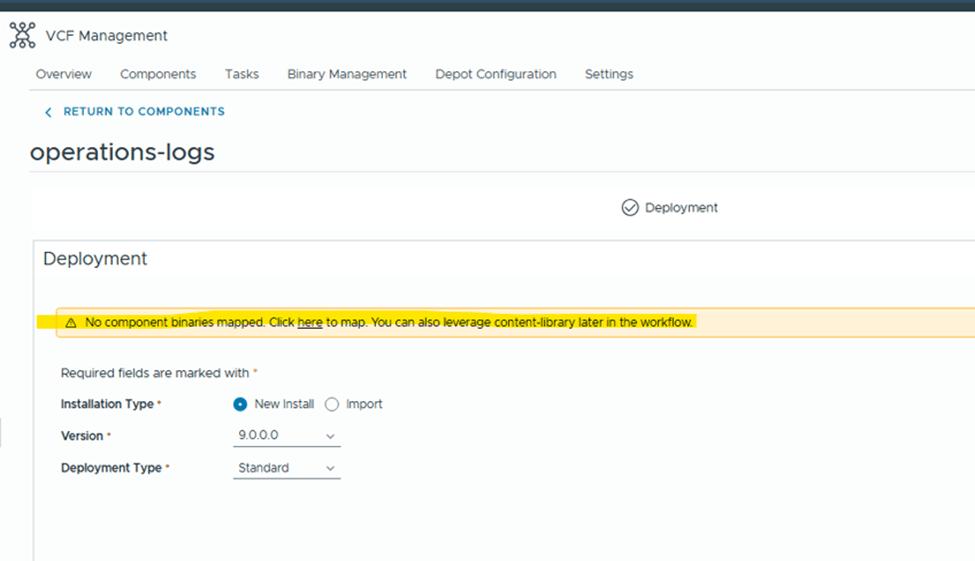
As you can see “MANAGE” option is only available for VCF Operations. And rest needs to be installed. If I click on ADD on any of those,
It says, NO component binaries mapped. Under binaries management, Depot is not configured.
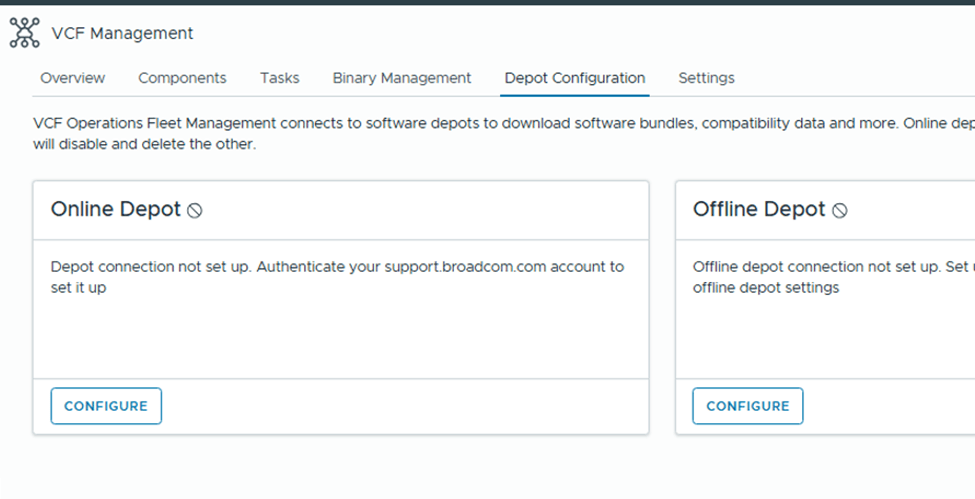
Under “Depot Config”, we have 2 options
Online Depot: Use this option if the appliance has internet connectivity and you have obtained download token from support.broadcom.com portal.
Offline Depot: This option requires you to setup either web server which has access to internet or local server where you would upload all binaries manually to.
For this example, I will be configuring “Online Depot” Click on “Configure” under online depot,
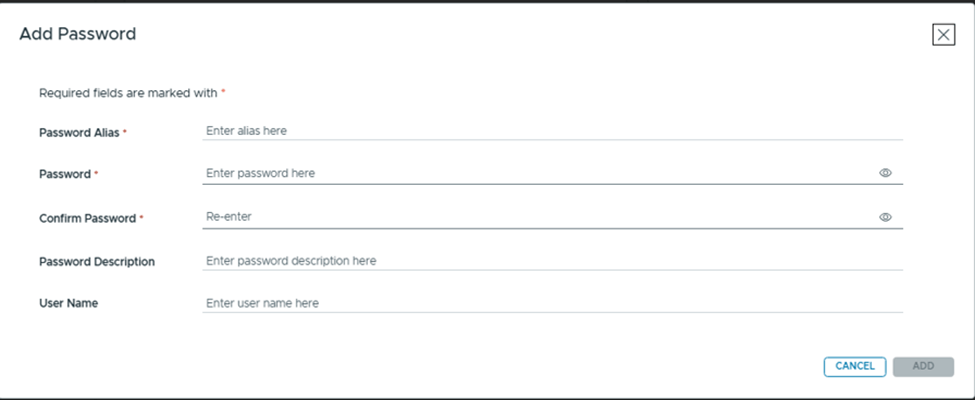
Click on the + sign on the right side,
Password Alias: Any friendly name. Password: Paste the token from Broadcom portal. (will explain later in this article on how to generate one) Confirm Password: Paste the same token again. Rest two are option fields.
Select the “Download Token” that we just created,
Accept the certificate and OK.
Online depot is now active.
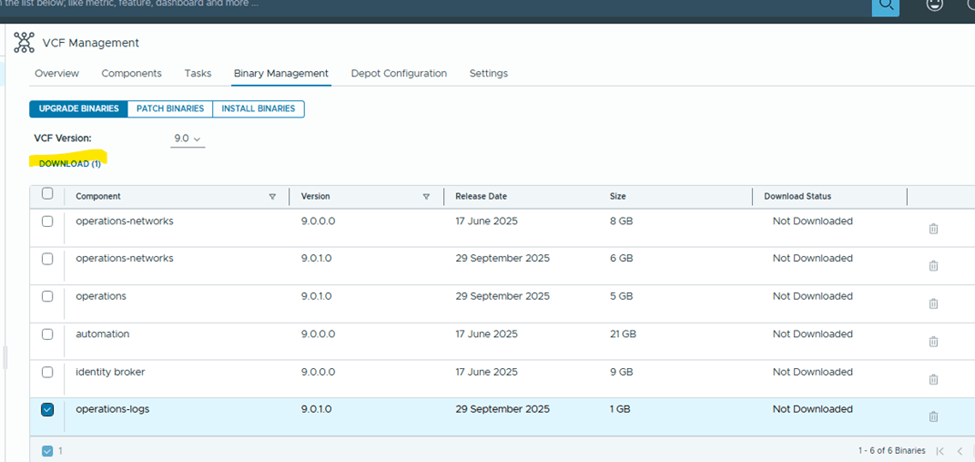
You would see all available products to download binaries for,
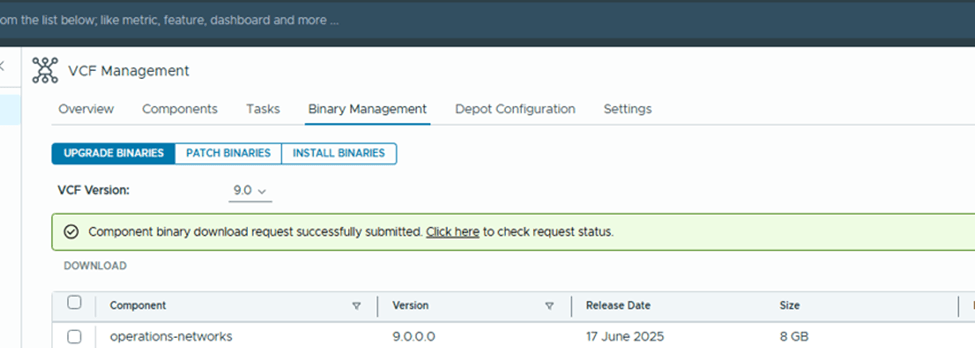
I selected “operations-logs” for testing and downloaded it,
You can monitor the status of the download under Tasks,
That’s it. You are good to download rest of the products.
VMware Cloud Foundation (VCF), deleting failed tasks is often necessary to avoid clutter in the SDDC Manager UI and free up resources. Failed tasks can also block further operations, especially credential rotation tasks.
Deleting failed tasks can help maintain a clean and organized SDDC Manager UI, making it easier to track ongoing and successful operations. Failed tasks can consume resources, potentially leading to performance issues or conflicts with other ongoing processes. Some failed tasks, like credential rotation failures, can block further credential operations until they are resolved or removed.
Deleting failed tasks is one of the prerequisites for rotating passwords via SDDC manager.
Let’s get into SDDC manager check failed tasks and delete them. This is typically done by using the SDDC Manager API or, if necessary, through manual SSH commands.
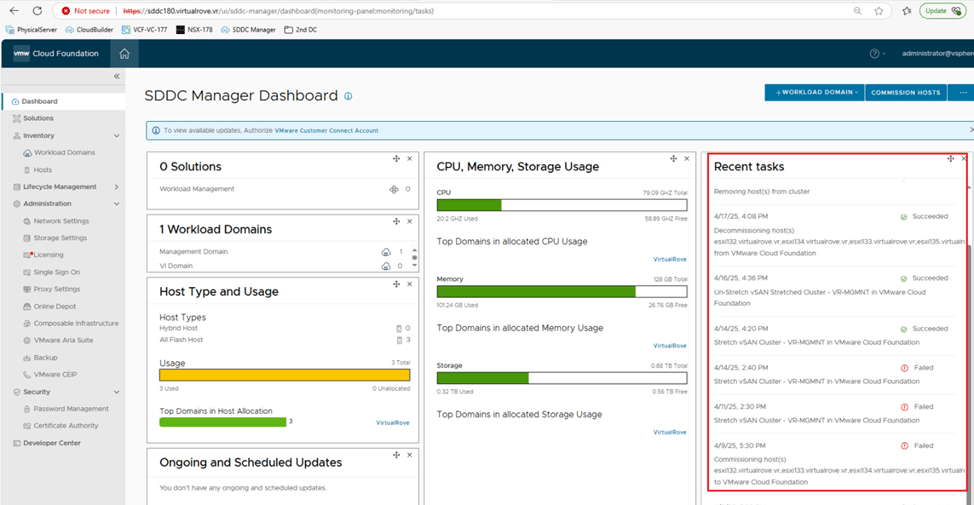
I see couple of failed tasks here on the dashboard of SDDC Manager. You can also find list of all tasks at the bottom here,
Click on the hyperlink of the task name,
Copy the task ID from the browser link,
SSH to SDDC manager using VCF account and switch to root user,
Just sharing a quick write-up on the error that I came across while working with VMware Aria Suite Lifecycle version 8.18 in my lab.
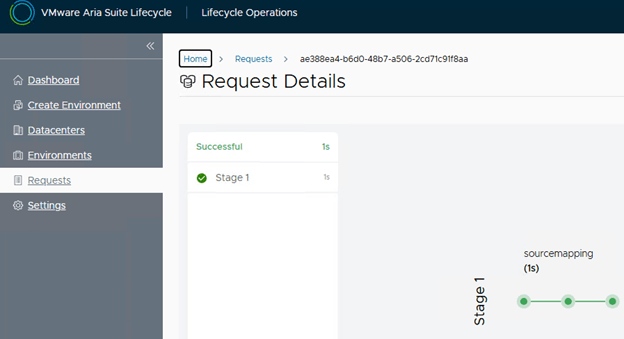
Error Code: LCMSOURCEMAPPING10018 Selected files checksums does not match with any product versions supported by VMware Aria Suite Lifecycle. One or more selected files checksums does not match with any product versions supported by VMware Aria Suite Lifecycle: [/data/VMware-vRealize-Log-Insight-8.18.4.0-24842179 (1).ova]
VMware Aria Suite Lifecycle 8.18 VMware-vRealize-Log-Insight-8.18.4.0-24842179
To deploy the log insight from Aria Suite (Formally known as vRLCM), you first need to upload vRLI binaries to vRLCM.
The source mapping error under requests in vRLCM
This is because of the supported version mismatch and missing product support pack or patch for vRLCM.
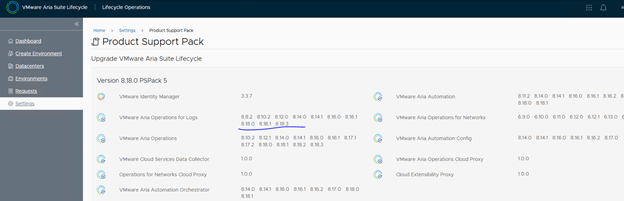
Go to Settings> Product Support Pack>
You will see the supported versions of the products that can be deployed from this instance of vRLCM
If you notice, for Logs, there is no 8.18.4 version listed. And the binaries that we are trying to upload is “VMware-vRealize-Log-Insight-8.18.4.0-24842179”
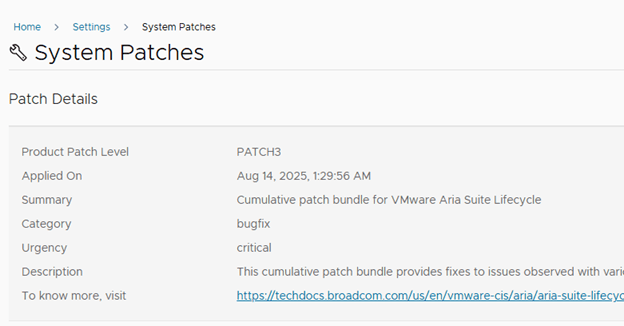
We need to get appropriate “product support pack” or patch installed to support this.
Following documentation detailed information on patches and packs needs to be installed.
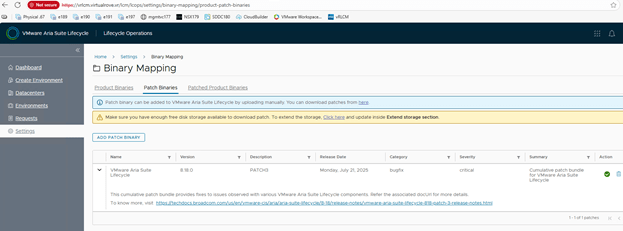
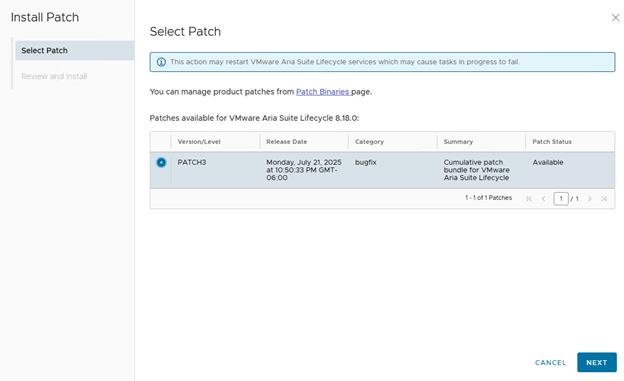
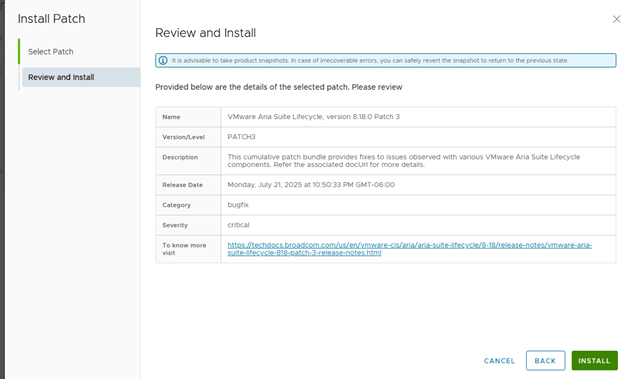
Lets check the release notes for “VMware Aria Suite Lifecycle 8.18 Patch 3”
In our last blog post, we added a host to the workload domain. Let’s deploy an edge cluster.
By default, VCF bring-up process configures / prepares the NSX env for VLAN backed segment and it does not include edges / edge cluster. You must deploy and edge cluster for software define routing and network services.
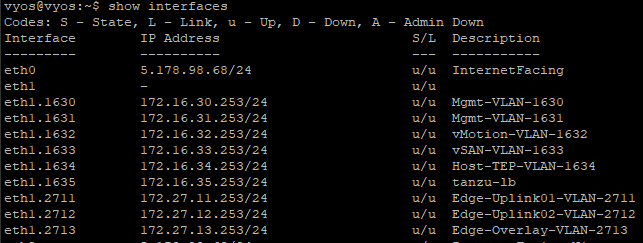
Lets get some pre-requisites in place before we start, We need couple of vlans configured on TOR to achieve an overlay networking, Host Overlay Vlan – Host TEP Edge Overlay Vlan – Edge TEP 2 Edge Uplink Vlans – To pair it with TOR for redundancy purposes.
Following is vlan configuration on TOR,
Lets verify it on TOR,
Next,
Prepare the deployment parameters in an excel sheet,
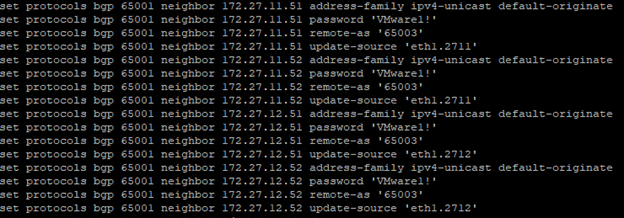
Next, Configure BGP on TOR,
Make sure to create a DNS record for edges and start the deployment,
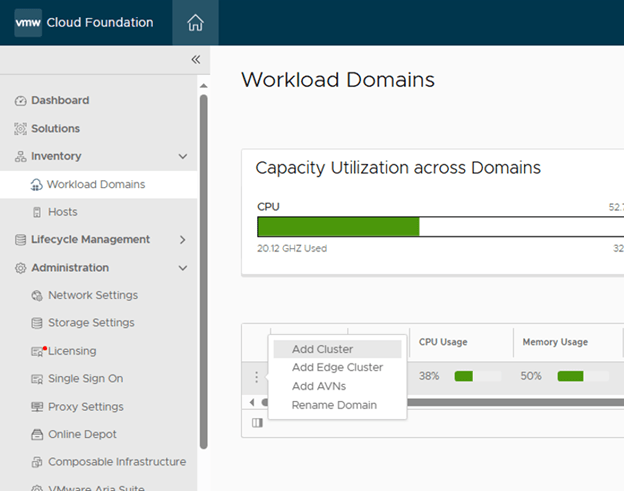
SDDC Manager > Workload Domains> Click on 3 dots besides the name and “Add Edge Cluster”
Check all Pre-requisites again and Begin,
Fill all the required details from parameters sheet that we created,
Additional cluster settings,
Kubernetes – Workload Management to create an NSX Edge cluster that complies with the requirements for deploying vSphere with Tanzu.
Application Virtual Networks to create an NSX Edge cluster that complies with the requirements deploying vRealize Suite components.
Custom if you want an NSX Edge cluster with a specific form factor or Tier-0 service high availability setting.
I have selected AVN here. You can select as per your use case.
Then the edge node settings, Type each edge node information and click “ADD EDGE NODE”at the end.
Verify the information on next page,
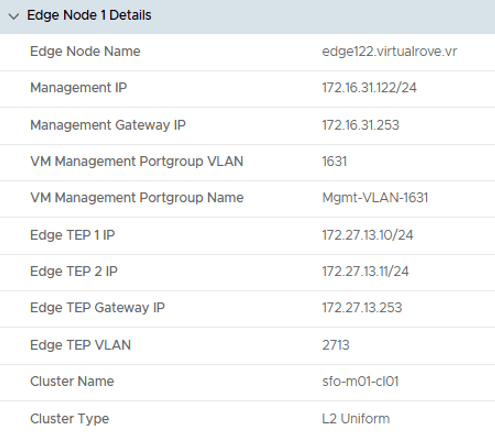
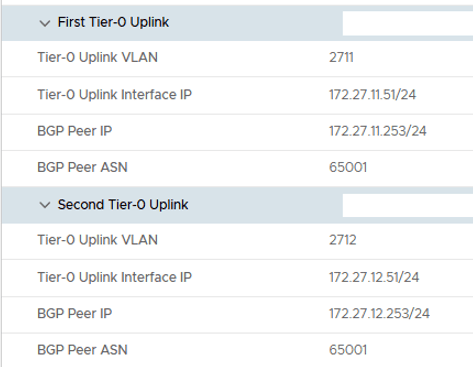
Node 1 details,
Node 1, Uplink details,
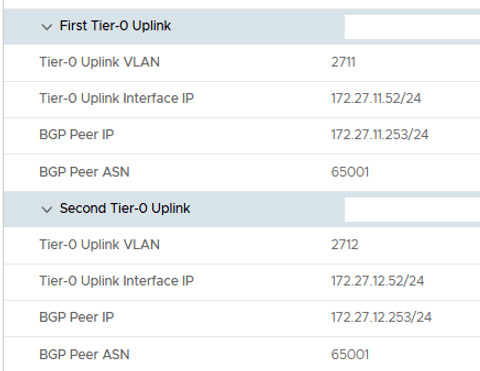
Node 2 details,
Node 2, Uplink details,
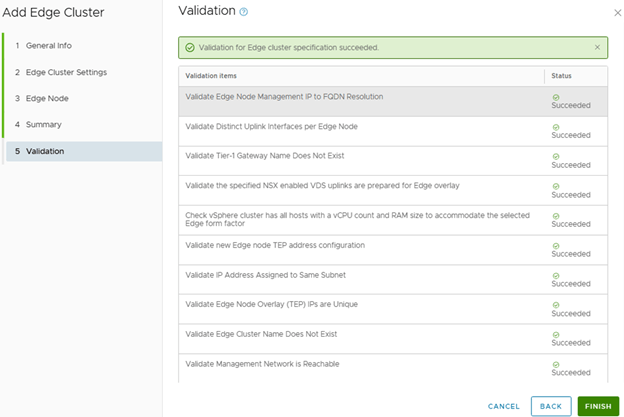
Review and fix any issues reported by validation and Finish,
Monitor the “Adding edge cluster vr-edge-cluster-01” in SDDC task details,
Task is successful and we see the edge cluster in SDDC UI,
On a high level, this workflow configures following…
Created 2 uplink port groups on vCenter VDS,
Two edges have been deployed,
Edge Cluster is created,
Transport Zone for edge vlan have been created,
Edge uplink profile have been created,
Both nodes have all these settings configured,
Active-Active Tier-0 gateway has been deployed,
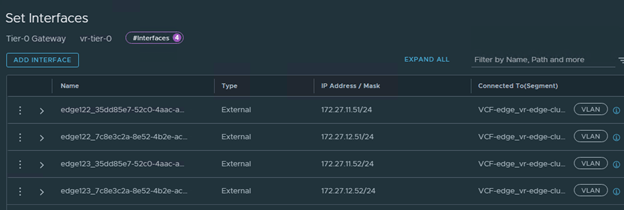
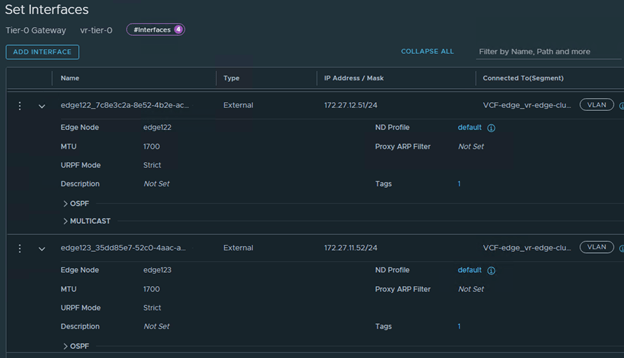
VLAN Backed uplink segments has been deployed to use it in interfaces configuration,
All interfaces looks good,
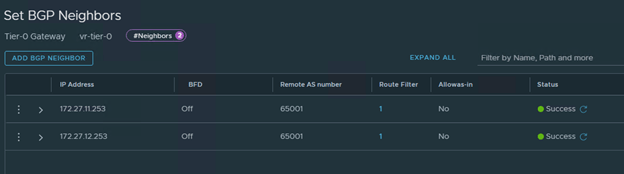
BGP is tuned on and 2 Neighbors configured,
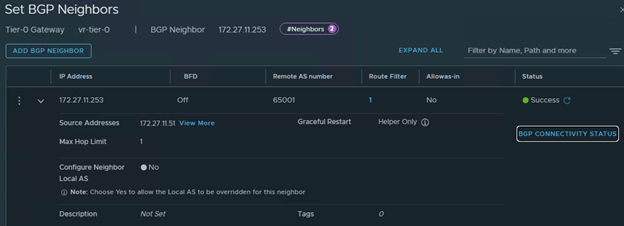
Check the BGP Connectivity status, Shows Established for both edges,
Route-Redistribution is in place,
And it has also deployed a Tier-1 gateway and connected to T-0,
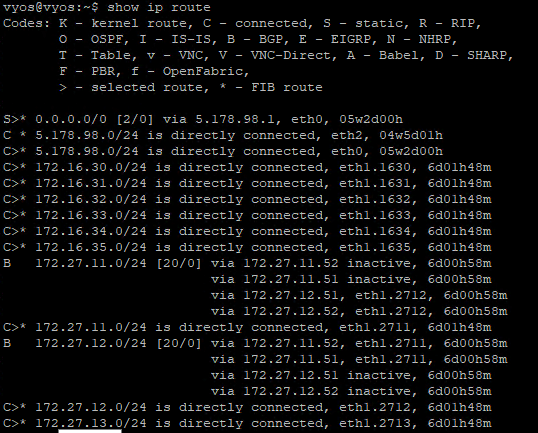
Wow, everything looks good. Lets check the BGP routes on the TOR,
All 4 BGP Neighbors shows up on the TOR,
BGP Routes looks good,
Nice.
Let’s create a test segment with 192.168.X.X CIDR and check if it appears in BGP route on TOR,
New segment has been created,
And we see the new route on TOR,
Here is how my network topology looks in NSX,
Hurray…!!!
All looks good. We are good to attach new VM’s to this overlay backed segment and it would get the connectivity to rest of the world.
Let’s get started with some documentation around adding / commissioning new host in an existing workload domain.
Add a Host to a vSphere Cluster Using the SDDC Manager UI
Verify that a host is available in the SDDC Manager inventory. For information on commissioning hosts, see Commission Hosts.
Commission Hosts
Hosts that use vSAN storage can only be used with vSAN-based workload domains.
Hosts that use NFS storage can only be used with NFS-based workload domains.
Hosts that use VMFS on FC storage can only be used with VMFS on FC-based workload domains.
Hosts that use vVols storage can only be used with vVols-based workload domains.
Ensure that a network pool supports the storage type you select for a host (vSAN, NFS, VMFS on FC, vVols).
Commissioning a host adds it to the VMware Cloud Foundation inventory. The host you want to commission must meet the checklist criterion below.
Ensure that each host you are commissioning meets the following criteria:
Hosts for vSAN-based workload domains are vSAN-compliant and certified on the VMware Hardware Compatibility Guide.
Hosts for NFS-based workload domains are certified on the VMware Hardware Compatibility Guide.
Hosts for VMFS on FC-based workload domains are certified on the VMware Compatibility Guide. In addition, the hosts must have supported FC cards (Host Bus Adapters) and drivers installed and configured. For compatible FC cards, see the VMware Compatibility Guide.
Hosts for vVols-based workload domains are certified on the VMware Hardware Compatibility Guide.
For vVols on FC-based workload domains, ensure that all ESXi hosts have access to the FC array before launching the workflow.
For vVols on NFS-based workload domains, ensure that all ESXi hosts must be able to reach the NFS server from the NFS network assigned in the IP pool.
For vVols on iSCSI-based workload domains, ensure that the iSCSI software initiator must be enabled on each ESXi host and the VASA provider URL must be listed as the dynamic target.
Two NIC ports with a minimum 10 Gbps speed. One port must be free, and the other port must be configured on a standard switch. This switch must be restricted to the management port group.
Host has the drivers and firmware versions specified in the VMware Hardware Compatibility Guide.
A supported version of ESXi is installed on the host. See the VMware Cloud Foundation Release Notes for information about supported versions.
DNS is configured for forward and reverse lookup and FQDN.
Host name must be same as the FQDN.
Self-signed certificate regenerated based on FQDN of host.
Management IP address is configured on the first NIC port.
Host has a standard switch and configured with 10 Gbps speed default uplinks starting with vmnic0 and increasing sequentially.
Hardware health status is healthy without any errors.
All disk partitions on HDD and SSD are deleted.
Network pool must be created and available before host commissioning.
Hosts for the vSAN-based workload domain must be associated with the vSAN enabled network pool.
Hosts for the NFS-based workload domain are associated with the NFS enabled network pool.
Host is configured with an appropriate gateway. The gateway must be part of the management subnet.
Before we get started, Here is new host config that will get added to existing management vi workload domain.
Hostname: esxi124.virtualrove.vr Memory: 16 GB pNICS: 2 Disks: 20gb 100gb 100gb , Total 220 RAW storage which will get added to existing VSAN storage. VM network vlan changed to VLAN 1630 NTP settings updated to use NTP server as “172.16.31.110” SSH and NTP service configured to “Start and Stop with the host” And regenerated self-sign certs for esxi. I have listed steps to regenerate in my previous blogs.
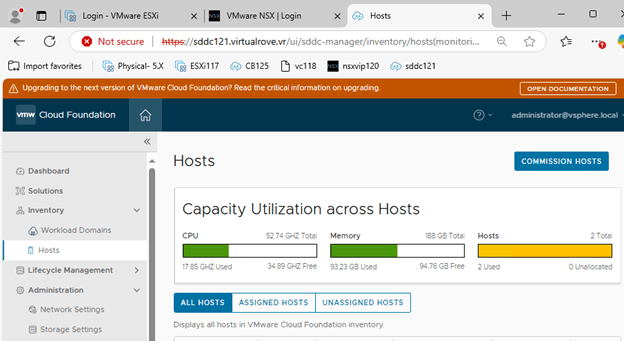
Login to SDDC Manager > Hosts > Commission Hosts,
Make sure all pre-requisites are met, Select All,
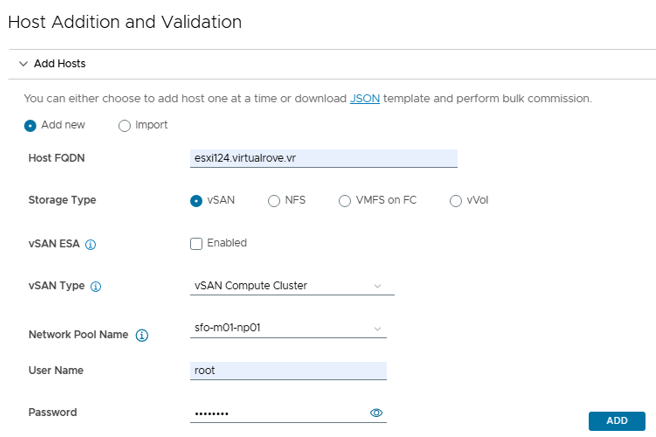
Next, Enter the required information and click on ADD
I have unchecked vSAN ESA, since am not using VSAN ready nodes as well as NO vLCM images. vSAN ESA is only supported in workload domains that use vLCM images.
vSAN Type is vSAN Compute Cluster.
Also, Select the existing “Network Pool” from the drop-down menu for vMotion & VSAN network,
Same can be verified on on SDDC manager under “Network Settings”
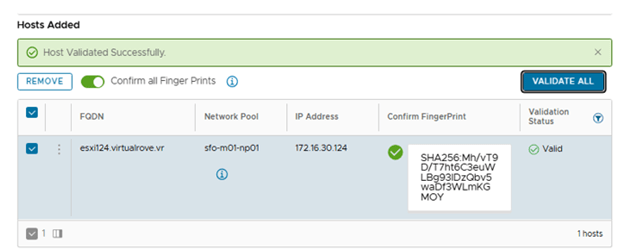
Once the host has been added, Turn on the radio button “Confirm All Finger Prints” and “VALIDATE ALL”
Review & Finish,
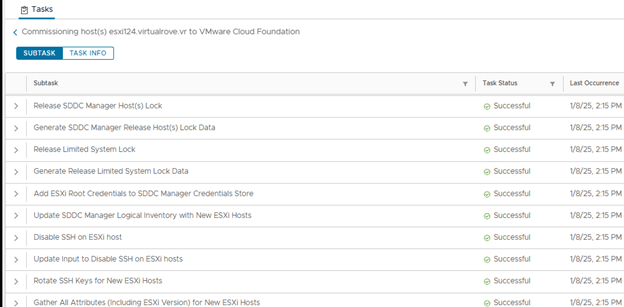
Monitor “ Commissioning host(s) esxi124.virtualrove.vr to VMware Cloud Foundation” task in SDDC task list,
Once finished, host will appear in the “UNASSIGNED HOSTS”
Lets get the new host added to the existing management vi domain after commissioning it, SDDC UI > Select Management Workload Domain > Clusters Tab > Click 3 dots to “ADD Hos”
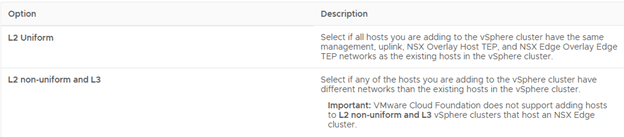
Select the commissioned host and select “L2 Uniform”
Important: VMware Cloud Foundation does not support adding hosts to L2 non-uniform and L3 vSphere clusters that host an NSX Edge cluster.
Finish.
Monitor the “Adding new host(s) to cluster” in SDDC task list,
On a high level, following steps are performed in “Adding new host to cluster”,
After initial validation, it adds the host to the cluster, Adds host to VDS Configures all vmknics Removes STD switch Configures HA Adds it to NSX by adding required transport zone as per the TNP and prepares it for NSX. And finally makes it available for workload migration / new workload.
Let’s review the environment after adding the host.
Host & Clusters view with all vmknics,
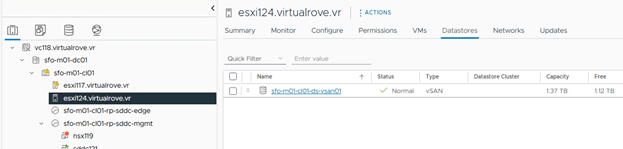
VSAN Storage added to existing cluster,
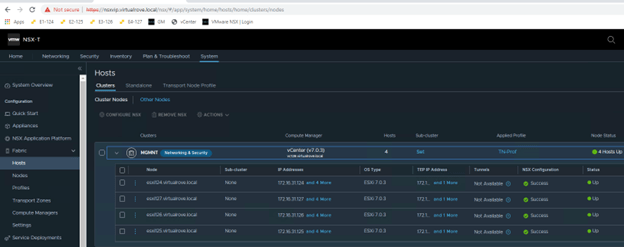
Hosts on SDDC Manager,
Workload domain host view,
New host has been prepared for NSX and ready for vlan backed segment,
That’s it for this post. Hope that it was helpful. We will add an edge cluster in our next blog.
With vCloud Foundation 5.2 version, you can import / convert your existing vSphere infrastructure as well as NSX env into the VCF and start managing it from SDDC manager.
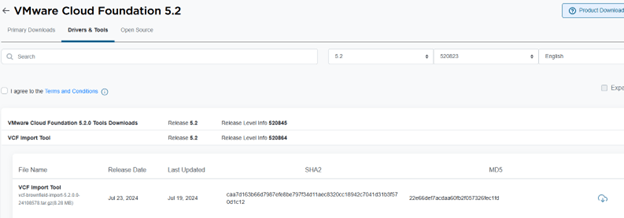
VCF import tool will help to achieve the same. The download link can be found here,
Let’s discuss some prerequisites before we move on,
Existing vSphere versions should be aligned with VCF 5.2 BOM. (ESXi & vCenter) No standard switch supported. DRS should be in fully automated mode and HA enabled on the cluster. Common / Shared storage between the hosts. (VSAN skyline health check compatible or with NFS3 version or FC storage) VDS should have physical uplinks configured. vCenter & SDDC Manager should be installed in the same cluster that we are converting. SDDC manager can be downloaded from the same location as VCF import tool. Cluster with vCenter should have minimum of 4 hosts.
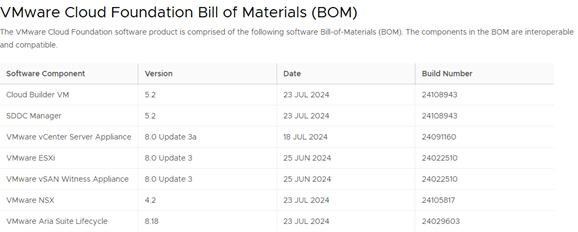
Here is the VCF 5.2 BOM for your reference,
Let’s get into lab and review the existing env,
I have a 4 hosts VSAN cluster with vCenter and SDDC installed in it. Remember, VSAN is not a requirement for this setup.
Review the ESXi & vCenter version,
SDDC manager installation is pretty simple and straightforward. You just need to download the ova and import it into the cluster. It will ask for some common parameters like hostname, ip schema & passwords for defined users. Once the SDDC boots up, you will see this on the screen of SDDC url,
“VMware Cloud Foundation is initializing… ”
Additionally, I have one single vds with 2 uplinks and some common port groups configured,
Let’s get into action and start working on getting this env into VCF.
WinSCP to SDDC appliance using VCF user and upload the VCF Import tool to vcf directory on SDDC,
Next, SSH to SDDC appliance,
Check the if the file has been uploaded and then extract the tar file using ‘ tar xvf’ command,
You will see multiple files getting extracted in the same directory,
Next, get into the ‘vcf-brownfield-toolset’ directory to run further commands,
The python script (vcf_brownfield.py) is located under “vcf-brownfield-toolset” directory.
We need to runt this script using some additional parameters,
I am skipping the nsx part of it by adding “–skip-nsx-deployment” towards the end of the command.
Next, script needs vCenter SSO credentials
Confirm thumbprint,
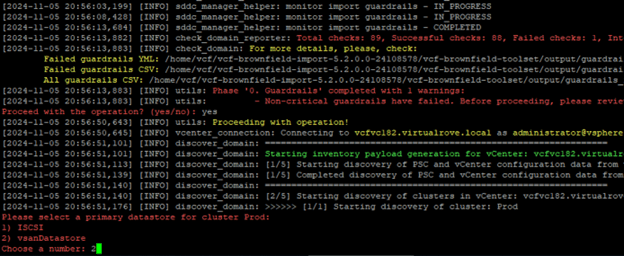
Monitor the script,
After finishing all required checks, it loads the summary,
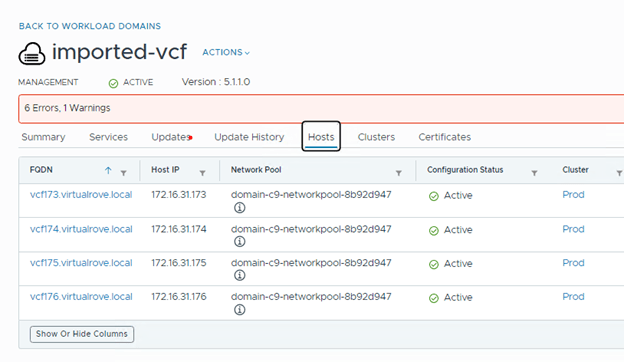
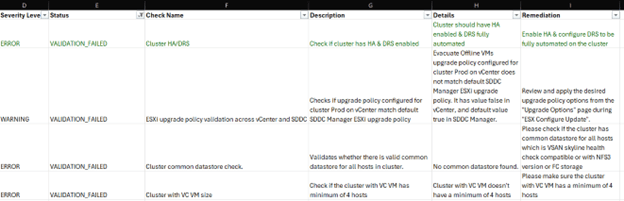
As we can see, 2 checks have been failed out of 89. It has also generated CSV file on SDDC manager. Lets have look at the logs and fix things as needed,
On SDDC manager, navigate to Output folder and download the CSV file,
The downloaded CSV file is easy to read, It shows the issue description and remediate it,
here is the sample…
Apply the filter for ‘Status’ column to see ‘VALIDATION_FAILED’.
As we see, it is complaining about HA / DRS being disabled on the cluster. I did that on purpose. And the next one is ‘WARNING’ and not an ‘ERROR’. However, found following article which talks about that warning,
“ESXi upgrade policy validation across vCenter and SDDC Manager”
When you are using the VCF Import Tool, certain guardrail messages may require you to perform a manual update to the SDDC Manager database. If you encounter any of these guardrail issues, modify the example commands to resolve the issues.
Got following error while upgrading NSX from v3.2.2 to v4.1.
Pre-upgrade checks failed for HOST: Connection between host 473cc672-2417-4a97-b440-38ab53135d02 and NSX Controller is UNKNOWN. Response : [Lcom.vmware.nsxapi.fabricnode.dto.ControlConnStatusDto;@edbaf5b Connection between host 473cc672-2417-4a97-b440-38ab53135d02 and NSX Manager is UNKNOWN. Please restore connection before continuing. Response : Client has not responded to heartbeats yet
We only have 3 hosts in the cluster. For some reason, it was showing 4th host “esxi164” in host groups which does not exist in the vCenter inventory.
Click on the host group to check the details.
Here is my vCenter inventory,
The host in the question (esxi164.virtualrove.local) was one of the old host in the cluster. It was removed from the cluster long back. However, somehow it is showing up in NSX upgrade inventory.
And as the error message says, NSX-T manager was unable to locate this to upgrade it.
“Connection between host 473cc672-2417-4a97-b440-38ab53135d02 and NSX Manager is UNKNOWN.”
The UUID mentioned in the error message had to be for missing host (esxi164.virtualrove.local). Because the UUID was not matching with any of the host transport nodes UUID in the cluster. You can run the following command on one of the NSX manager to get the UUID’s of the nodes.
get transport-nodes status
Or you can click on the TN node in NSX UI to check the UUID.
If you click next on the upgrade page, it will not let you upgrade NSX managers.
So, the possible cause for this issue is, the old host entry still exists in the NSX inventory somewhere. And it is trying to locate that host to upgrade it.
As we can see from the output, “current_step_title: Preparing Installation”. Looks like something went wrong while the host was being removed from NSX env and its state is still being marked as “state: pending” in NSX manager database.
I recently came across a situation where the NSX-T Edge vm in an existing cluster was having issues while loading its parameter. Routing was working fine and there was no outage as such. However, when a customer was trying to select an edge vm and edit it in NSX UI, it was showing an error. Support from VMware said that the edge in question is faulty and needs to be replaced. Again, routing was working perfectly fine.
Let’s get started to replace the faulty edge in the production environment.
Note: If the NSX Edge node to be replaced is not running, the new NSX Edge node can have the same management IP address and TEP IP address. If the NSX Edge node to be replaced is running, the new NSX Edge node must have a different management IP address and TEP IP address.
In my lab env, we will replace a running edge. Here is my existing NSX-T env…
Single NSX-T appliance,
All hosts TN have been configured,
Single edge vm (edge 131) attached to edge cluster,
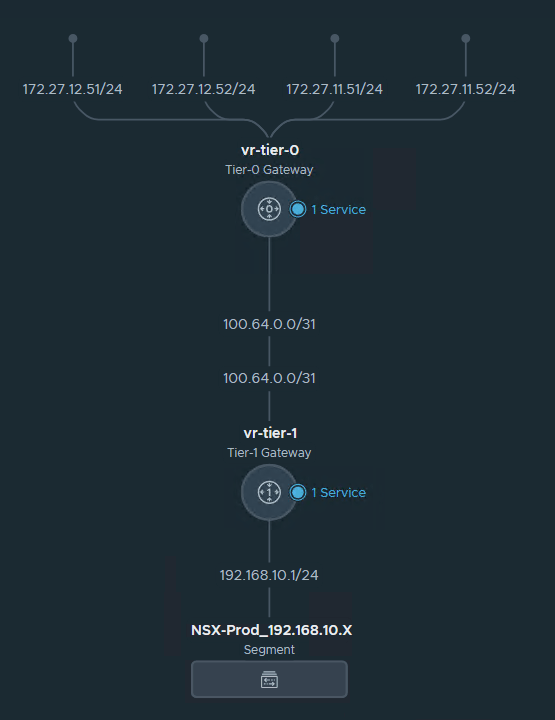
One test workload overlay network. Segment Web-001 (192.168.10.0/24)
A Tier-0 gateway,
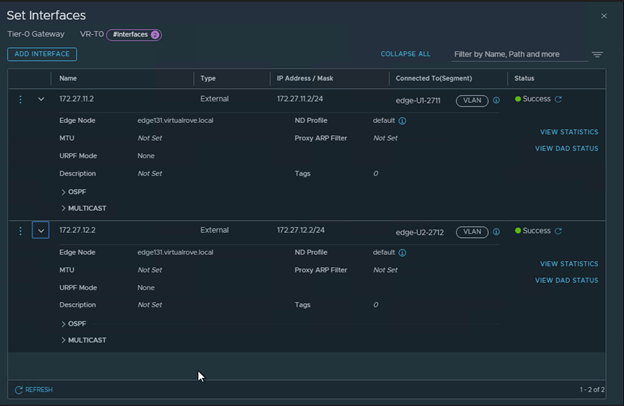
Note that the interfaces are attached to existing edge vm.
BGP config,
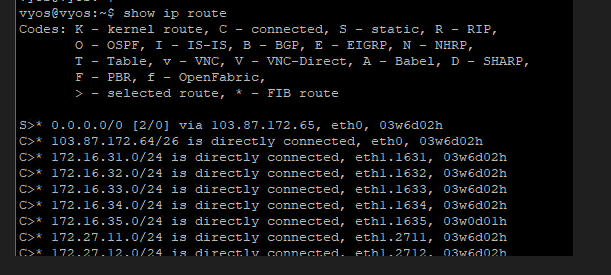
Lastly, my VyOS router showing all NSX BGP routes,
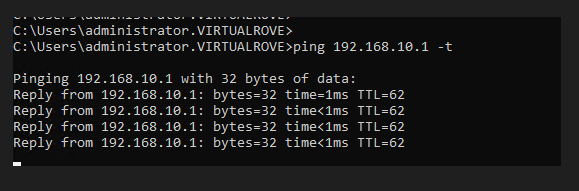
Start continuous ping to NSX test overlay network,
Alright, that is my existing env for this demo.
We need one more thing before we start the new edge deployment. The new edge vm parameters should match with the existing edge parameters to be able to replace it. And the existing edge showing an error when we try to open its parameters in NSX UI. The workaround here is to make an API call to existing edge vm and get the configuration.
Please follow the below link to know more about API call.
Let’s get started to configure the new edge to replace it with existing edge. Here is the link to the blogpost to deploy a standalone edge transport node.
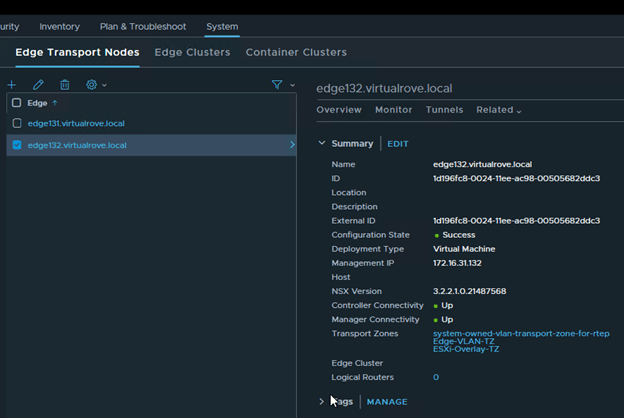
New edge vm (edge132) is deployed and visible in NSX-T UI,
Note that the newly deployed edge (edge132) does not have TEP IP and Edge cluster associated with it. As I mentioned earlier, The new edge vm parameters should match with the existing edge parameters to be able to replace it.
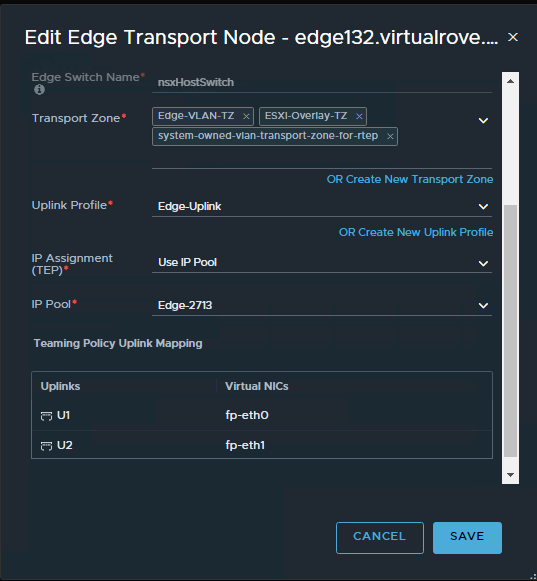
Use the information collected in API call for faulty edge vm and configure the new edge vm the way you see it in the API call. Here is my new edge vm configuration looks like,
Make sure that the networks matches with the existing non working edge networks.
You should see TEP ip’s once you configure the new edge.
Click on each edge node and verify the information. All parameters should match.
Edge131
Edge132
We are all set to replace the faulty edge now.
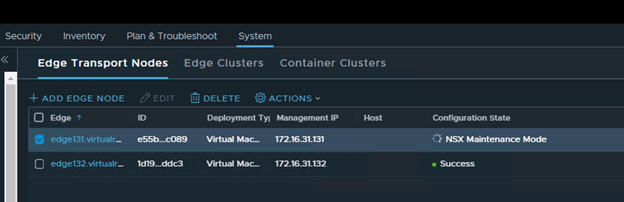
Select the faulty edge (edge131) and click on actions,
Select “Enter NSX Maintenance Mode”
You should see Configuration State as “NSX Maintenance Mode” in the UI.
And you will lose connectivity to your NSX workload.
No BGP route on the TOR
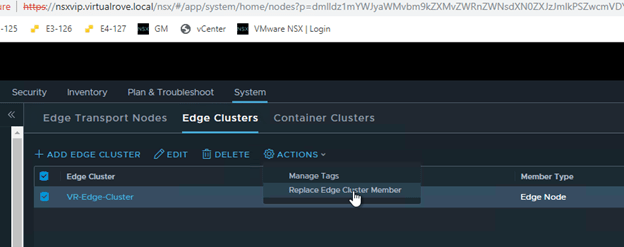
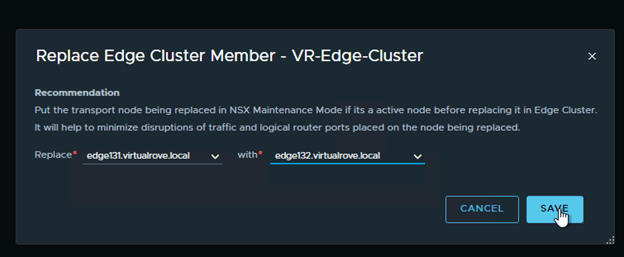
Next, click on “Edge Clusters”, Select the edge cluster and “Action”.
Choose “Replace Edge Cluster Member”
Select appropriate edge vm’s in the wizard and Save,
As soon as the faulty edge have been replaced, you should get the connectivity to workload.
BGP route is back on the TOR.
Interface configuration on the Tier-0 shows new edge node.
Node status for faulty edge shows down,
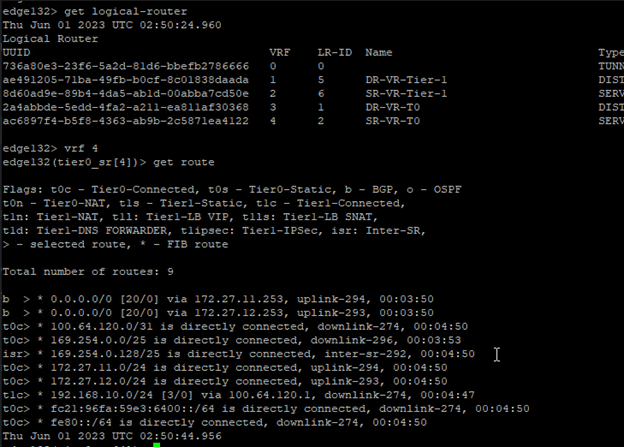
Let’s get into the newly added edge vm and run “get logical-router” cmd,
All service routers and distributed routers have been moved to new edge.
Get into the SR and check routes to make sure that it shows all connected routes too,
We are good to delete the old edge vm.
Lets go back to edge transport node and select the faulty edge and “DELETE”
“Delete in progress”
And its gone.
It should disappear from vCenter too,
Well, that was fun.
That’s all I had to share from my recent experience. There might be several other reasons to replace / delete existing edge vm’s. This process should apply to all those use cases. Thank you for visiting. See you in the next post soon.